
Most people know that the Auto Scaling Group’s main goal, it’s to monitor our servers to guarantee the best capacity for a specific application and make it run smoothly without impact on the end user. Also, automatically adjust the capacity according to the traffic, keeping the best cost possible.
However, Auto Scaling does more than that. There are several features that most people are not aware of.
Today, you will learn and become an expert about Auto Scaling Lifecycle Hooks and how they could help you to resolve complex problems.
The Lifecycle Hooks make it possible to listen to events that happen within the Auto Scaling Group with any EC2 instances managed by it. That allows us to trigger and perform any actions when some events occur.
Auto Scaling Lifecycle Hooks: Save Logs from your EC2 before you lose it!
Let’s see how this solution work-flow works:
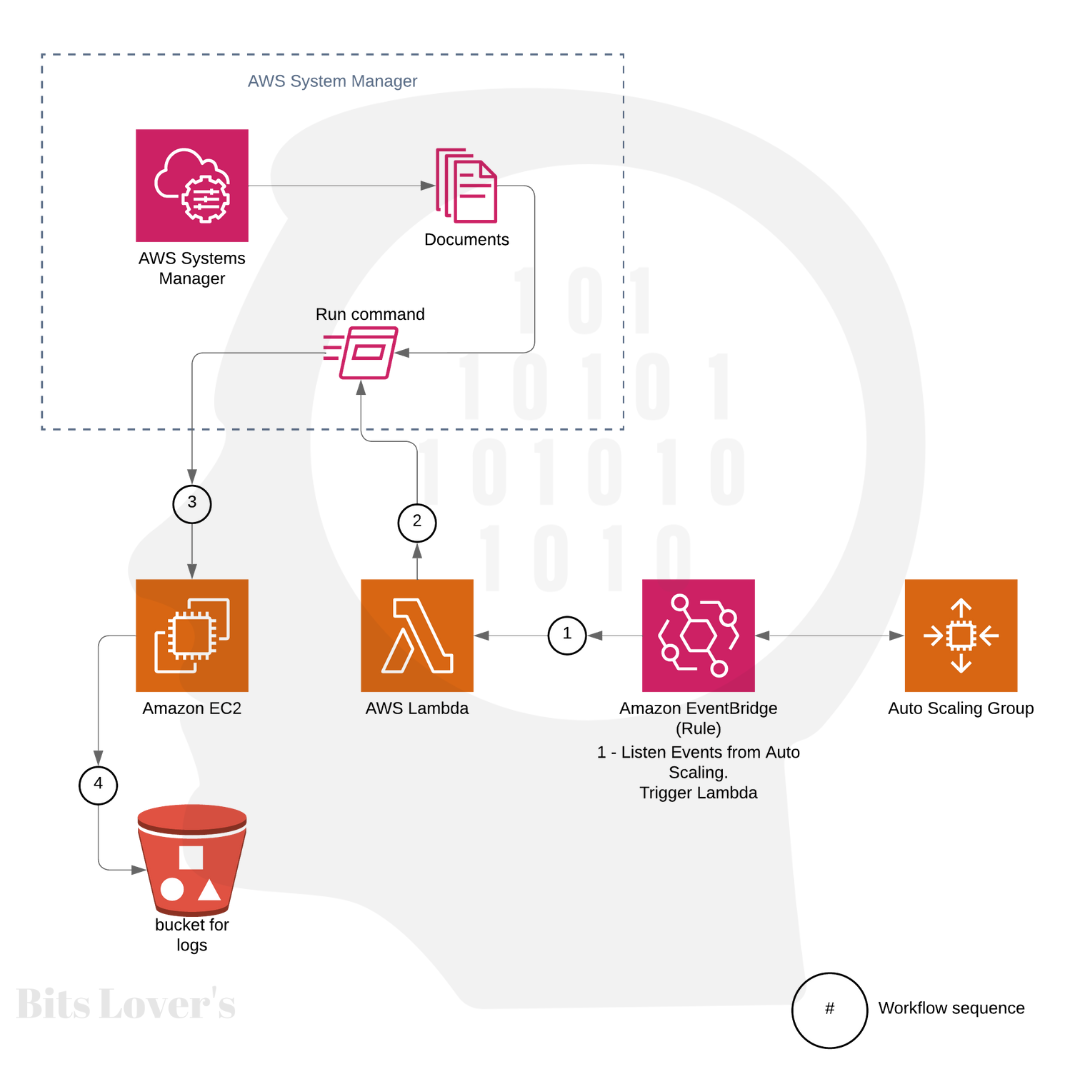
Cool, right? Let’s deep dive.
But why saving logs, it’s important? Well …
When someone tells me that we lose the server and logs! Me:

Sometimes, bad things happen with our application, and our instances fail on the Load Balance health check, which makes the Load Balance flag an instance as unhealthy, stopping sending traffic to it.
If your Auto Scaling Group is configured and is enabled to consider the Load Balance Health Check status to replace a bad instance, the instance will be terminated, and some files will be lost.
So, whatever the problem with the instance, we will never know the root cause because we will lose the logs on the server that could tell us the root cause.
So, to resolve that issue, we will use the Lifecycle Hook to trigger an event that will save the instance logs to an S3 Bucket, where later you can download the logs and do your troubleshooting.
What do you need to save your logs on AWS?
So believe it, the solution it’s pretty simple. You can save any log file from any EC2 instance before terminating it.
Before we create the solution, let’s see a summary of which services and resources from AWS it’s required to build the whole solution:
1 – Auto Scaling Group.
2 – AIM Role for the Instance.
3 – AWS EventBridge (the old CloudWatch Events)
4 – Lambda Function
5 – IAM Role for Lambda
6 – Document (from SSM, Systems Manager)
7- Run Command (from SSM)
8- Load Balance (Not required)
9- AWS SNS (Simple Notification Service – Not Required)
You have noticed that we don’t need too many services and resources. And to make this whole solution only requires a few minutes.
How do Auto Scaling Lifecycle Hooks work?
There are two representations for the health status of an instance: healthy or unhealthy. All instances in your Auto Scaling group begin in a healthy state. Instances are expected to be healthy unless Amazon EC2 Auto Scaling gets a warning that they are unhealthy. This warning can come from one or more subsequent sources: Amazon EC2, Elastic Load Balancing (ELB), or a custom health check.
So, after Auto Scaling receives an unhealthy status, the EventBridge Rule will catch that event from Auto Scaling. Then, the EventBridge Rule will trigger a Lambda Function.
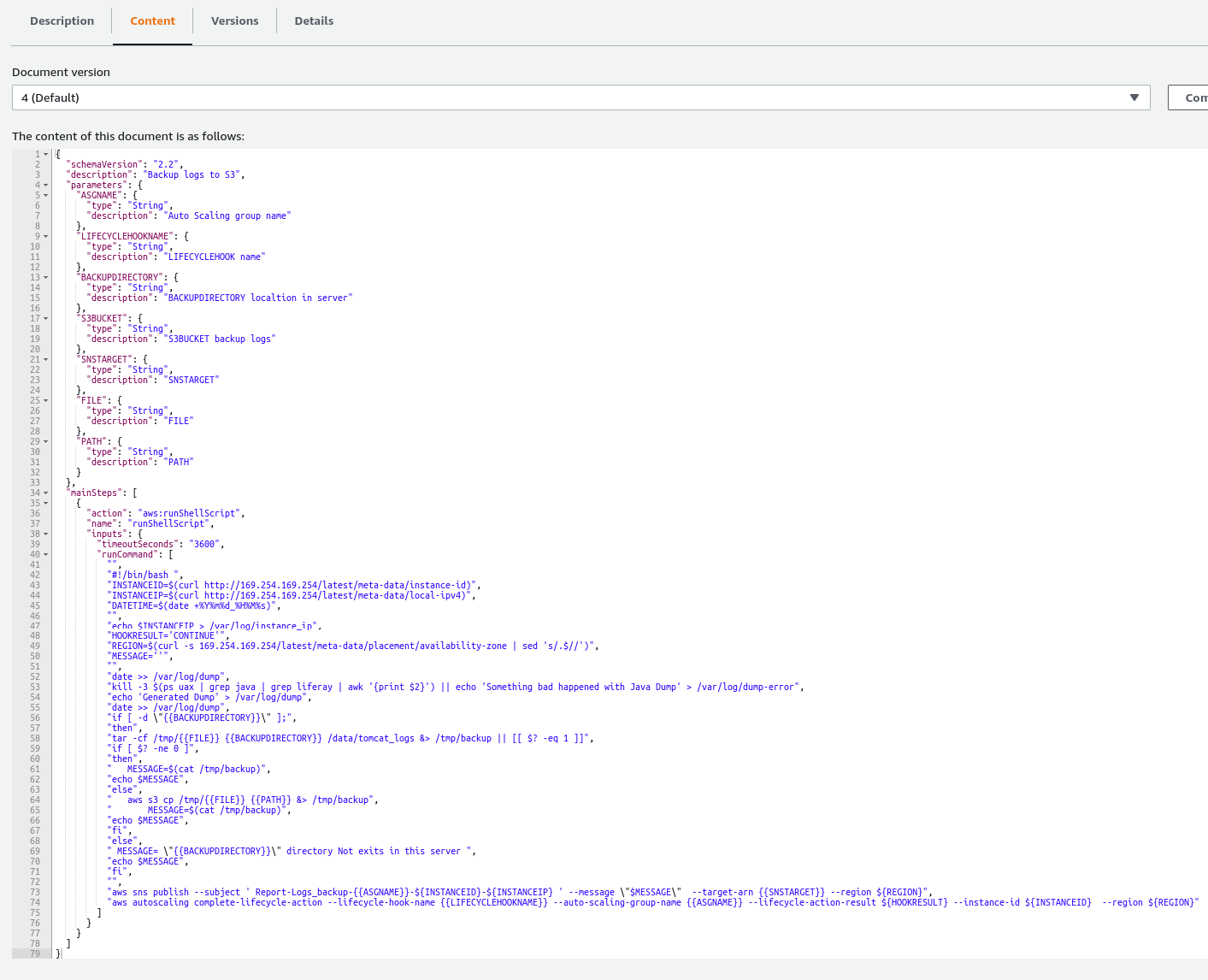
Our Lambda Function was written using Python 3.9. And the main goal for this Lamdba function is to run a script (Document) using Run Command from SSM (Systems Manager) that contains the steps we defined to execute in EC2. So, in other words, the steps that we need to do before terminating the instance, in our case, we are creating a tar file and uploading all logs files that it’s interesting to us.
Before terminating the instance, our script also calls the SNS service to send a notification every time an instance is terminated. However, this step is optional and requires an IAM Role to allow the Lambda function to call the SNS service.
The last and required step from our script, it’s to call the Auto Scaling service to Complete the Lifecycle Action: we are done, and we can go ahead and terminate the instance.
It’s a straightforward process. Now let’s deep dive and see all steps necessary to implement it on the AWS:
Create the IAM Role for your EC2
If you already have one existing EC2 with Role, you can add a new inline policy. Like this:
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"autoscaling:CompleteLifecycleAction",
"sns:Publish",
"s3:*"
],
"Effect": "Allow",
"Resource": "*"
}
]
}
Also, add the AWS Policy AmazonEC2RoleforSSM, to allow the EC2 instance to act for SSM.
Also, remember to give access to your EC2 instance on the S3 bucket, where you plan to save your logs.
Note: Remember to give access to your EC2 instance to write new objects on the S3 bucket, where you plan to save your logs.
Create IAM Role for the Lambda
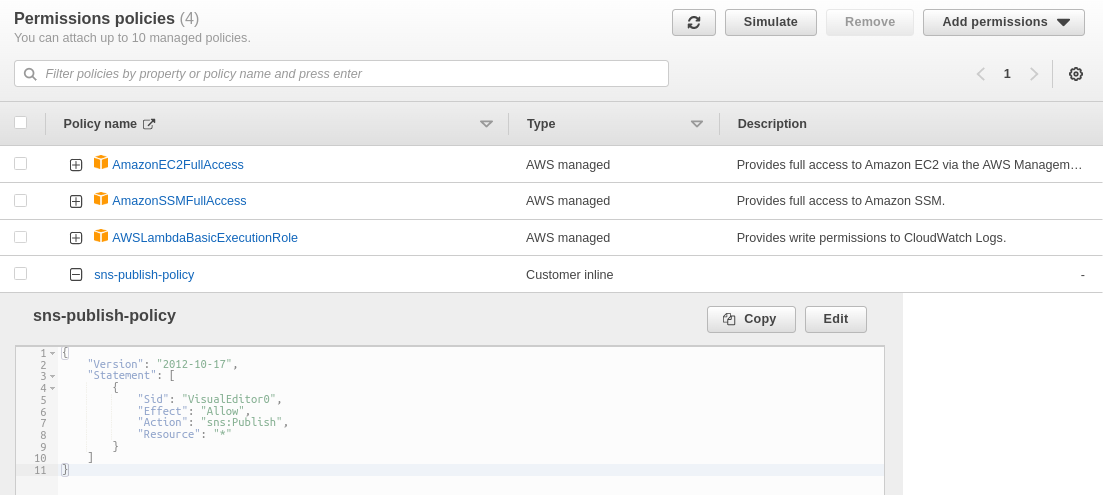
We need to create a Role for our Lambda function, and we must add the policies, AWSLambdaBasicExecutionRole and AmazonSSMFullAccess. Furthermore, if you need to send emails using Lambda, we need also create an inline policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"sns:Publish"
],
"Effect": "Allow",
"Resource": "*"
}
]
}
Create a Lifecycle Hook on the Auto Scaling Group
We need to configure our existing Auto Scaling Group to enable our new Lifecycle and make it available for the EventBridge Rule.
Navigate to AWS Console and select your existing Auto Scaling Group, and on the details screen, go to the “Instance Management” tab.
You will see something like this:
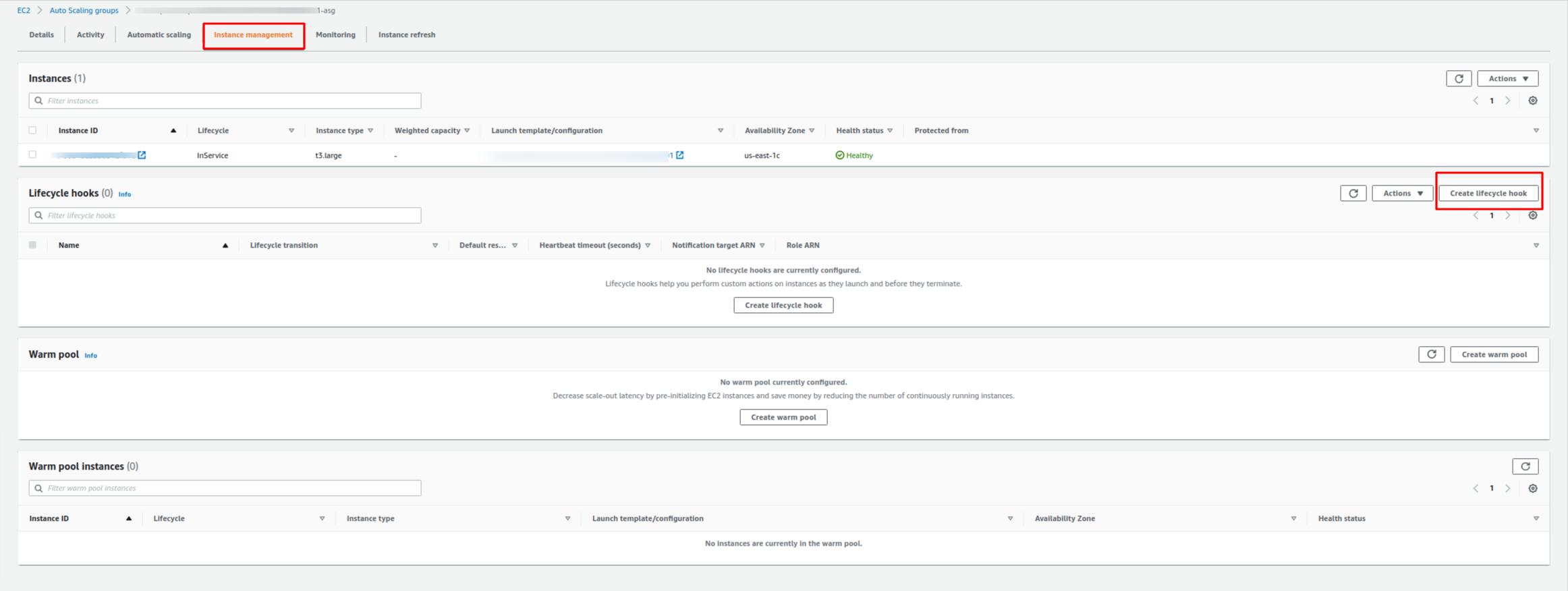
Later, click on “Create lifecycle hook,” and then this screen will show up:
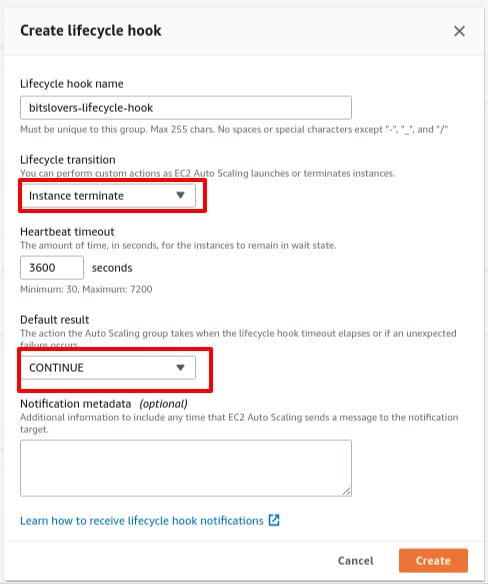
Give a friendly name for the Lifecycle Hook. Also, selecting the value “Instance Terminate” on the “Lifecycle transition” option means appending one listener to all events that will terminate any EC2 from this Auto Scaling Group. Also, select “CONTINUE” for the “Default Result” option.
Heartbeat Timeout
The heartbeat timeout is the time, in seconds, for the instance, in a wait state. So, be careful when you define that value.
Why?
If your server contains several big files that you need to back up, it means that you will need more time (increase the heartbeat timeout). Otherwise, the process will be stopped, and you will lose the backup because the upload process may be interrupted.
You are a winner! You are almost there! Let’s go.
Now we have our Auto Scaling prepared and visible for any Termination event. It means that these Auto Scaling group events will be caught by any Rule from the EventBridge.
So, when Auto Scaling raises the intention to terminate an instance, EventBridge needs to be aware that such an event will happen. So, we need to create one Rule on the EventBridge, then our Lambda function will be triggered. But we will create the EventBridge Rule later.
Create a System Manager Document:
An AWS Systems Manager document (SSM document) represents the Systems Manager’s operations on your managed instances. On Systems Manager it’s available several pre-configured documents that you can reuse by defining parameters at Runtime. You can find Pre-configured documents in the Systems Manager Documents console by picking the Owned by Amazon. Documents utilize JavaScript Object Notation (JSON) or YAML, and they introduce steps and parameters that you define.
In our scenario, we will create our version of the SSM Document. You can download our script from the GitHub account:
Let’s see the steps that we need to do on AWS Console to create our SSM Document.
Under “Management & Governance,” you will find the “Systems Manager” service.
Give one Name for your SSM Document, and on the content, copy and paste our document.json file from our GitHub repository. Later, click on “Create document“.
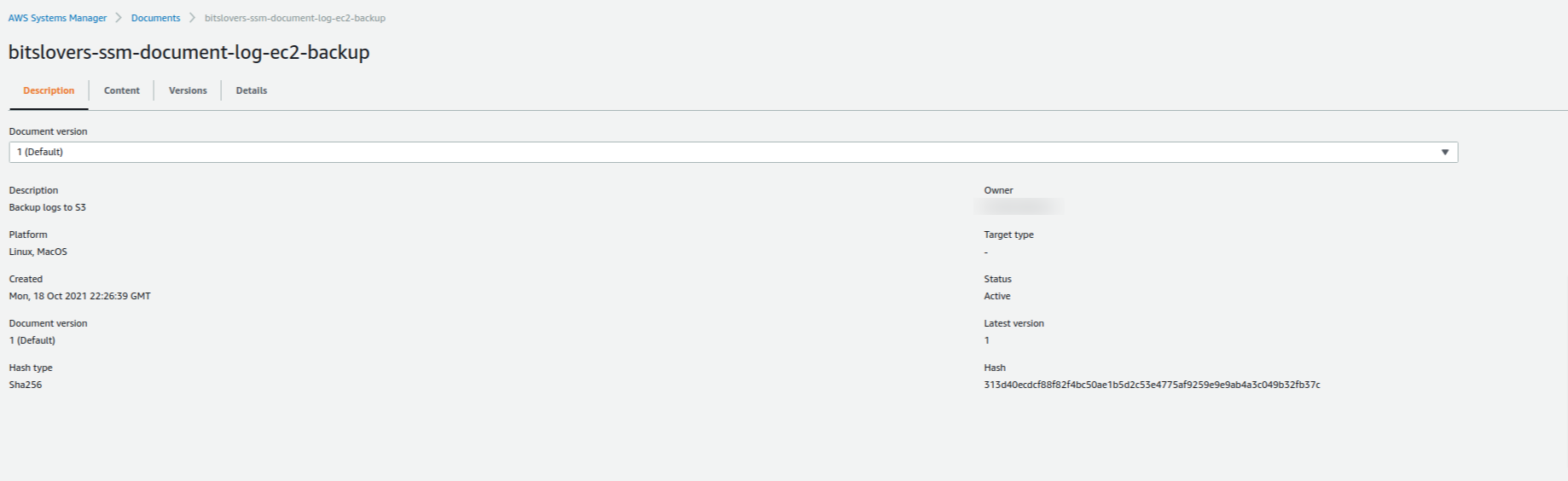
Easy, right? Let’s see the details from our Document, and it should look like this one:
Also, you can see the Details tab, we can see all the required parameters that this Document needs:
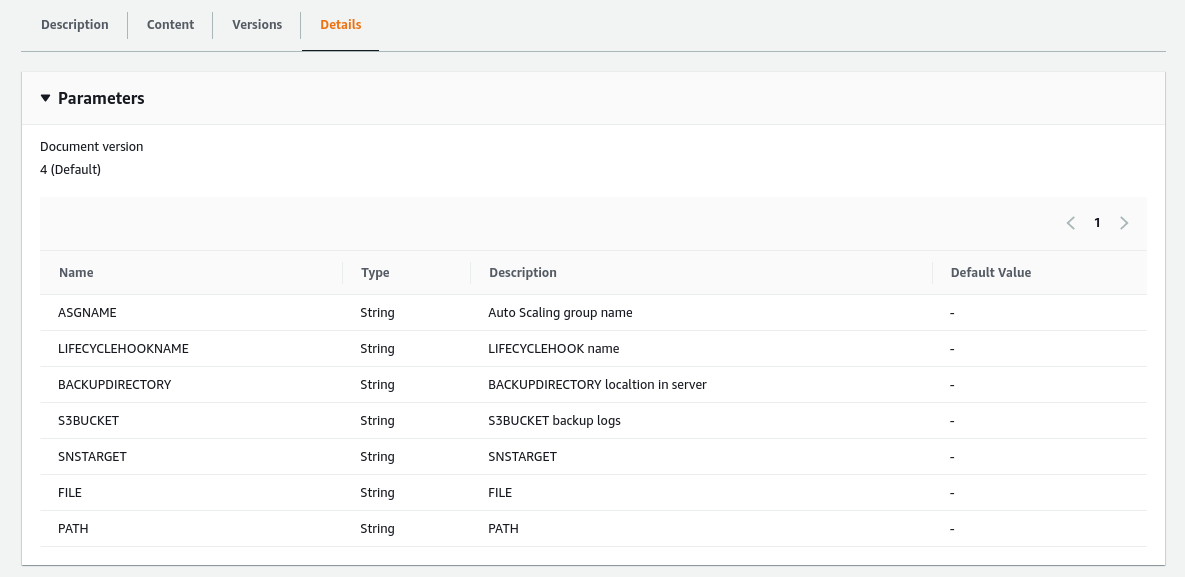
It’s important to highlight that our CloudWatch will provide the parameters ASGNAME, LIFECYCLEHOOKNAME, from this Document. And the other variables our Lambda function will provide.
Create Lambda Function
The AWS Lambda function utilizes modules incorporated in Python 3.9 and the module boto3. The function executes the following steps:
- Checks whether the SSM document exists.
- Sends the command (Run Command) to the EC2 instance that is designated for termination.
- Checks for the status of Run Command, and if it fails, the Lambda function finishes the lifecycle hook.
Let’s create the lambda function:
- Log in to the AWS Lambda console, and select Create Lambda function.
- For Name, type any name, and for Runtime, choose Python version 3.9.
To simplify the Lambda function code, paste the Lambda function (lambda_ssm_call.py) from the GitHub repository.
Later, we need to define the environment variables for our Lambda function. So, we need to specify:
1 – S3BUCKET -> it’s the S3 Bucket name to store the EC2 Logos.
2 – SNSTARGET -> It’s the ARN for your topic on SNS (it’s optional).
3 – SSM_DOCUMENT_NAME -> it’s the SSM Document that we created before.
It will look like this one:
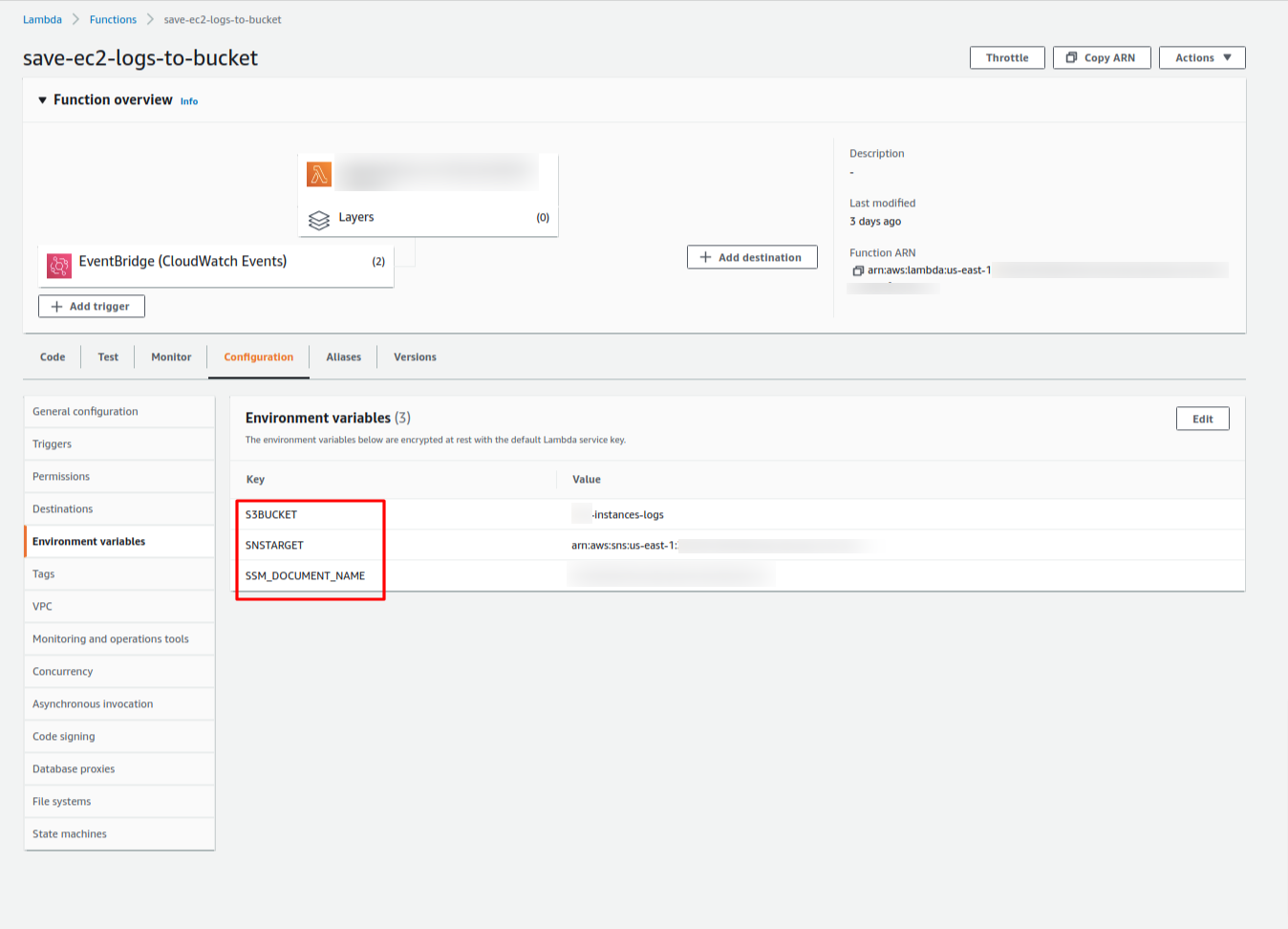
We are almost there! I promise you!
Our final step it’s to create the EventBridge Rule, to link all services and resources together.
Create EventBridge Rule
Go to the EventBridge and later, select the Rule:
Now, let’s specify all configurations that we need:
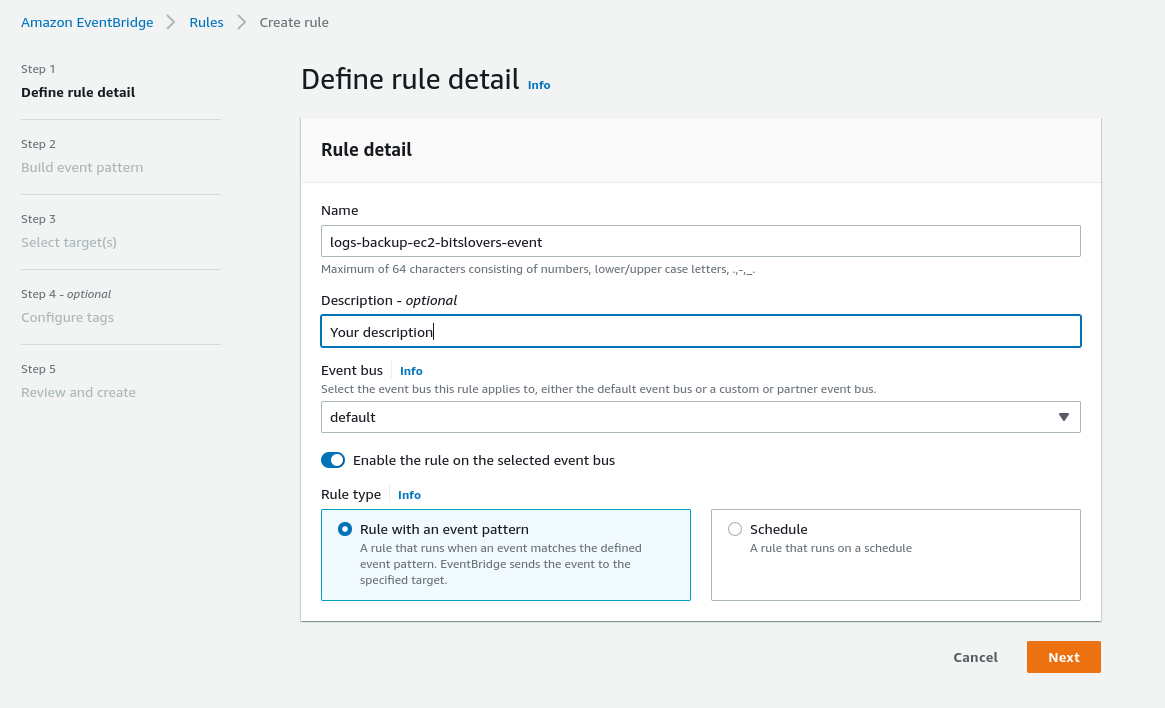
1 – Name: Give a unique name for your Rule.
2 – Keep the option enabled: Enable the rule on the selected event bus.
3 – Select the option: Rule with an event pattern
4 – Click on the Next button.
Build Event Pattern
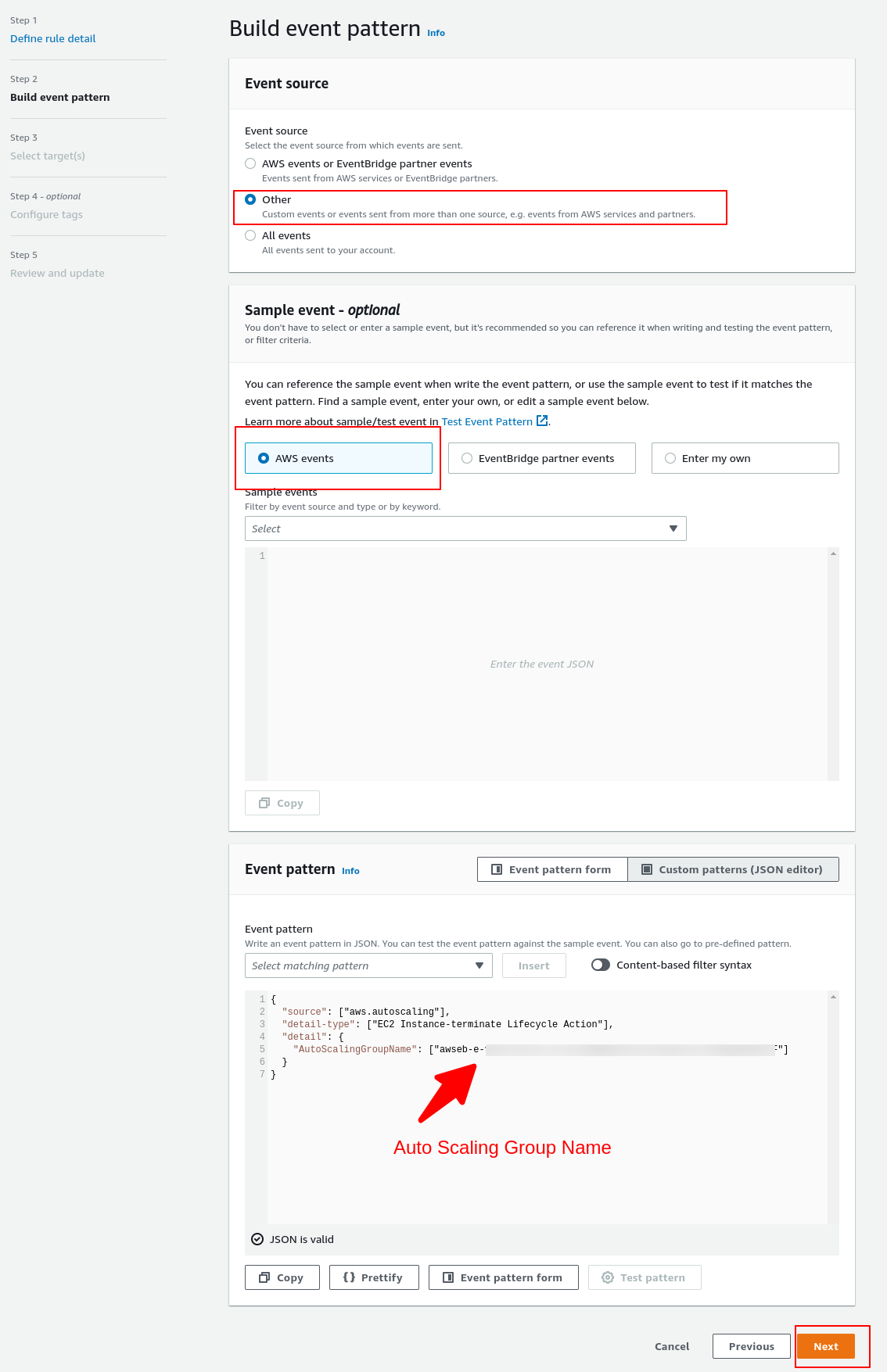
From the screenshot above, you need to pay attention to these configurations:
1 – Event Source: Other
2 – Sample Event: AWS Events
3 – Event Pattern: Here, you need to append all Auto Scaling Group names that you would like to listen to the events.
Following this pattern:
{
"source": ["aws.autoscaling"],
"detail-type": ["EC2 Instance-terminate Lifecycle Action"],
"detail": {
"AutoScalingGroupName": ["your-asg-name"]
}
}
And for the Targets session:
Select your Lambda function created in the previous step.
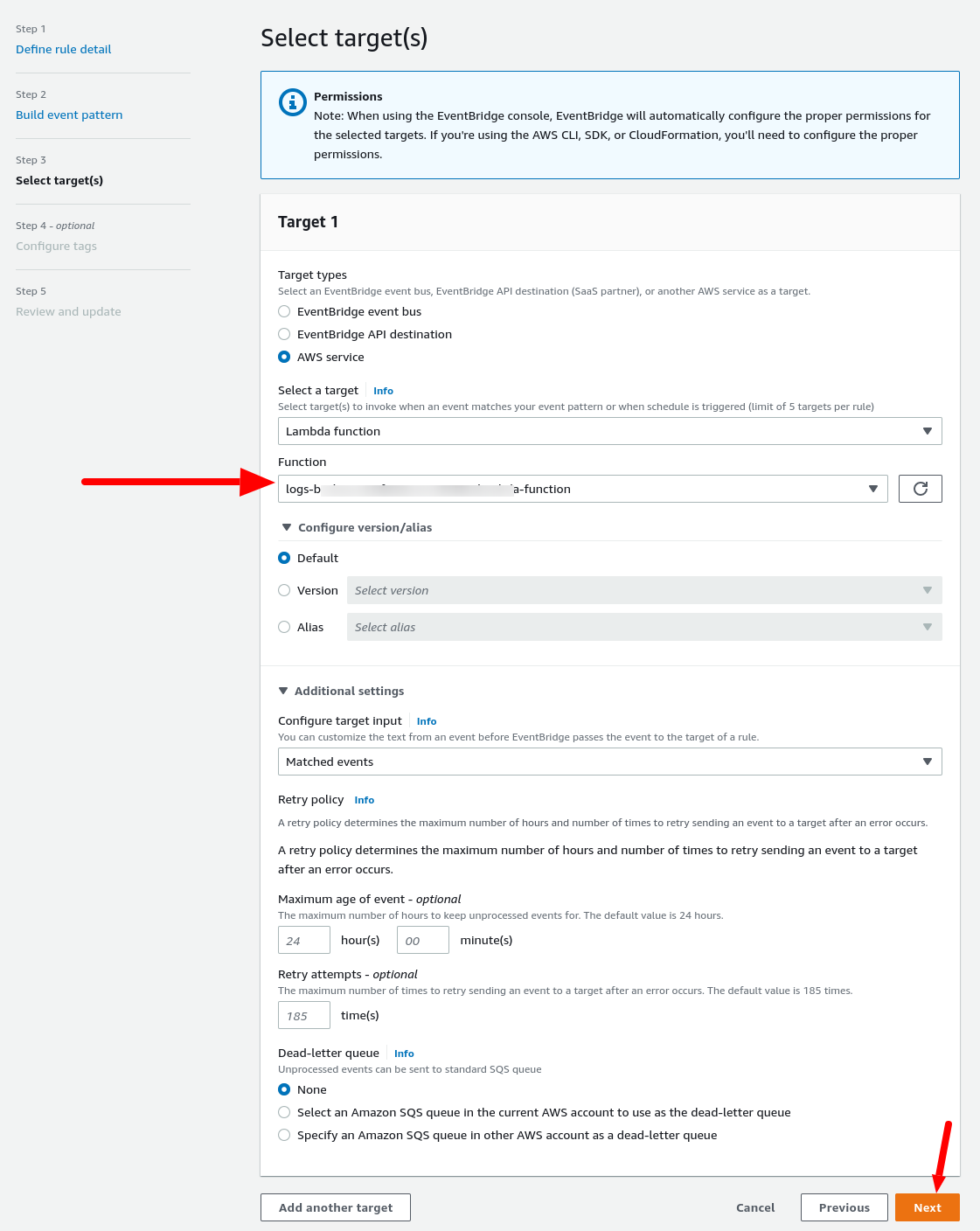
Finally! We are done with all configurations.
You may ask yourself: How is the best way to test it?
Goood question… BTW 🙂
⚡ Do you want to deploy this solution in seconds? 🚨
👉 You can save a lot of time using the Terraform Module that deploys all resources needed in a few seconds and only 2 input variables.

Testing and Trigger Auto Scaling Hook
It’s always a good idea to test, right? Let’s keep our minds in peace.
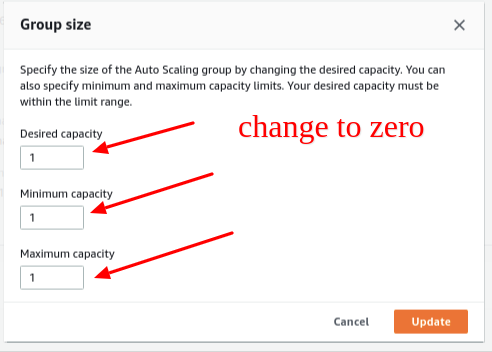
You can set the Desired Capacity and the Minimum Capacity from the Auto Scaling Group to 0. Later, the Auto Scaling Group will terminate all EC2 instances. Also, the lifecycle status turned to Termination: Wait, which you can observe from the Instances tab. Later the AWS Lambda function will be triggered by AWS EventBridge Rule.
You can examine your CloudWatch Logs to examine the Lambda function output. From the CloudWatch Console, select Logs and then /aws/lambda/{function_name} to view the execution result.
Also, you can go to your S3 bucket and check the uploaded files. You can also check AWS SSM Command history from the EC2 Console to see if SSM accurately executed the command.
Checking the Logs
If you notice that the process is not working, there are some places where you could check the logs to figure out which error may occur in the background. For example, if our script that saves the logs fails, we can check the logs on Run Command within System Manager.
On System Manager → Run Command:

You can see all attempts done when the events were triggered; from our screenshot above, you can notice that the status is “Failed.” If you click on the command id, you can see more details:

On the Run Command history, in the session “Target and Outputs”, you can click on Instance ID to display the logs. Also, you can see which parameters the Run Command received from the Lambda function, it’s very useful for troubleshooting.
Ops!? Something is missing…
If you see some message like this:
is not authorized to perform: autoscaling:CompleteLifecycleAction on resource
from your logs…
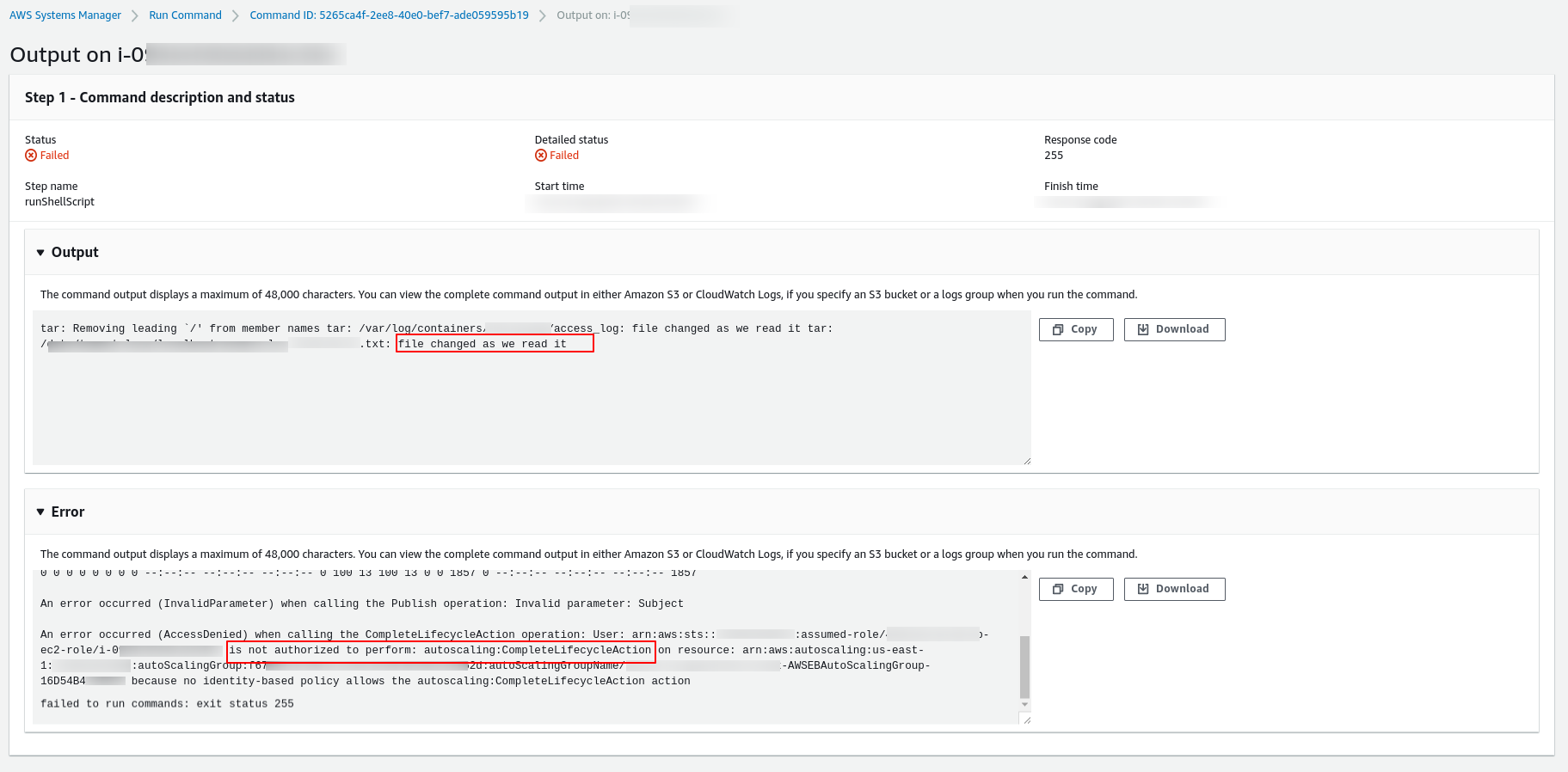
It means that the EC2 instance we are trying to terminate is not allowed to call the Auto Scaling service to finalize the termination process. So, we need to change the IAM Role for this instance and include the policy above.
You can see on the screenshot above the Output and Error message from our script (Document) that was executed inside our EC2 instance.
Before you Leave! Do you have 1 minute?
Please leave a comment and let me know your opinion and suggestion! I really appreciate it.
Conclusion
Now that you’ve observed an example of how you can link several AWS services together to automate the backup of your EC2 instance files by relying solely on AWS services. I hope you are encouraged to design your solutions.
Also, you may notice that the Auto Scaling lifecycle hooks, Lambda, and Run Command are essential tools because they enable you to react to Auto Scaling events automatically, such as when an instance is terminated. Nevertheless, you can also apply the same approach for other solutions like exiting processes appropriately before an EC2 instance is terminated, deregistering your EC2 from service managers, and scaling stateful services by moving state to other running instances. Your imagination only restricts the possible use cases.
[adinserter name=”Block 8″]
Another scenario in that we can use Lifecycle Hooks, it’s to register or deregister GitLab Runner when your pipeline is finished with a heavy task. So, basically, we could create and destroy Runners on-demand.
plz make a video as same document
The SSM Document is not working for IMDSv2 instance.
TOKEN=`curl -X PUT “http://169.254.169.254/latest/api/token” -H “X-aws-ec2-metadata-token-ttl-seconds: 21600″` \
&& curl -H “X-aws-ec2-metadata-token: $TOKEN” -v http://169.254.169.254/latest/meta-data/
how can I use double quote in that JSON?