Common Issues with AWS Health Check
Take these actions if AWS is not replacing your bad EC2 instance. I helped several DevOps Engineers in different companies with a common issue that sometimes makes us anxious to figure out the root cause.
The 90% percent of cases where the server is unhealthy (or the application is not responding) and your current configuration didn’t replace the EC2. You need to check a few configurations and fix the problem. Continue reading and figure out how you can resolve it quickly.
Questions Scenarios
I will describe to you some scenarios and configurations that may match yours:
1 – Configuration
If you have a Load Balance (regardless of the type) and your EC2 instance is attached to an Auto Scaling Group.
1.2 – Problem:
The application is not responding, and the EC2 is not terminated or replaced.
1.3 – Check:
Check if your Auto Scaling Group looks for the Health Check from the Load Balance to determine if the EC2 is in Health or Unhealth state.
Find your Auto Scaling Group from your EC2, and edit it. Then, in the Details session, look for Health Checks. Check if the Health Check Type is equal to EC2 & ELB.
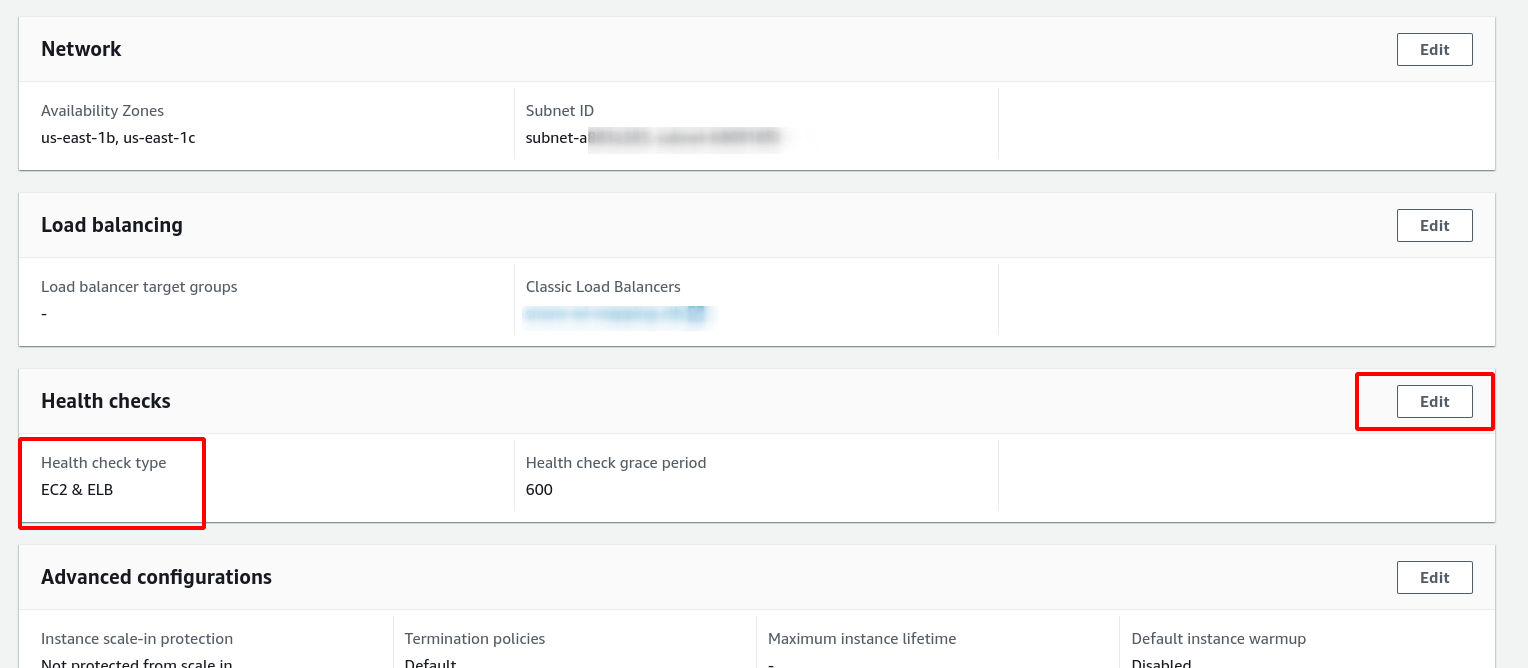
If not, your Auto Scaling Group is not using the Load Balance Health Check to flag the EC2 Health. So, to fix it, you need to edit this configuration.
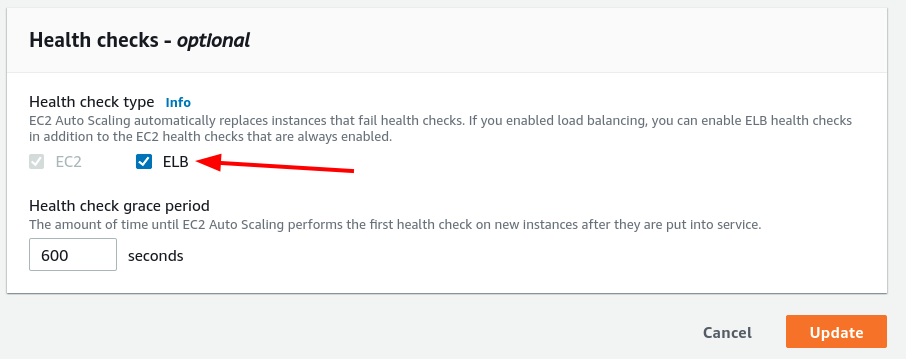
Problem 2
If your Auto Scaling Group is looking at the Health Check of Load Balance but still not replacing an EC2 instance when your application is not responding, it may be another configuration.
1.3.2 – Verify Health-Check metrics in your load balance
The AWS Load Balance Health Check contains some attributes that allow us to define metrics to identify precisely when we should be considered a Health or UnHealth state for our server.
Below are some configurations:
Remember that the Health Check configuration is located within the Target Group if you use Application or Network Load Balancer.
Classic Load Balancer
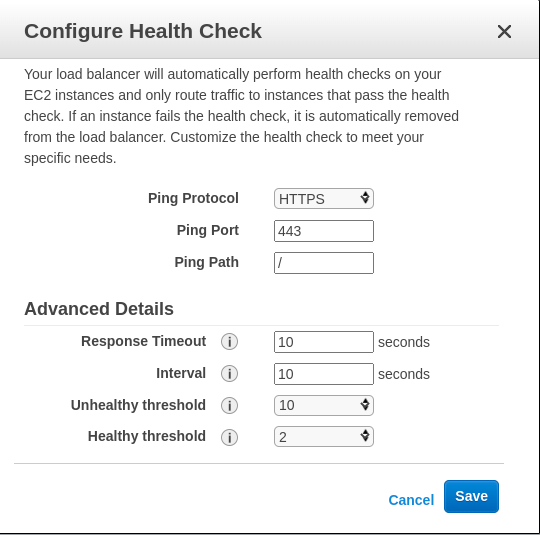
Network or Application Load Balancer
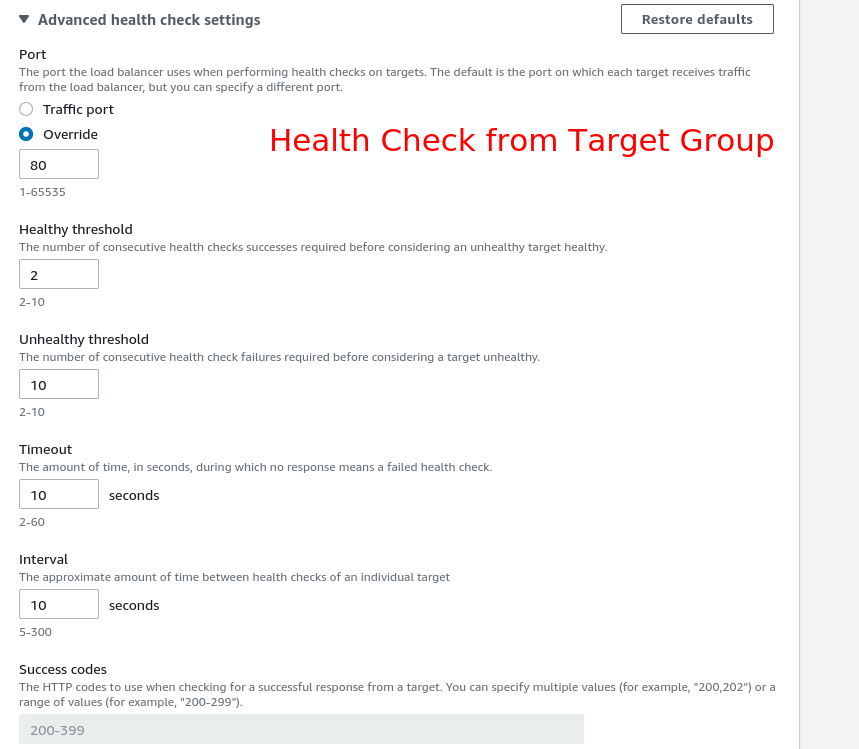
Response Timeout
In seconds, the amount of time to wait when receiving a response from the health check.
HealthCheck Interval
The portion of time between health checks of a particular instance, in seconds.
Unhealthy Threshold
The number of successive failed health checks must happen before reporting an EC2 instance unhealthy.
Healthy Threshold
The number of successive successful health checks must happen before reporting an EC2 instance healthy.
Health Check – Example
For example, if you define the metrics above with high values, your load balancer will take a considerable time to detect an unhealthy instance. For example, the Healthy Threshold is too small, and the Unhealthy Threshold is too high.
So, if you configure your configuration like this (like the previous screenshot):
Unhealthy Threshold = 10
HealthCheck Interval = 10
Response Timeout = 10
Your instance status will be Unhealthy only after 1000 seconds. But, it could be worst. Let’s imagine the same scenario where we still have the values for those attributes above and the Healthy Threshold is 2.
For one application that is not entirely out of service, for example, sometimes it returns HTTP 200, which means that our endpoint for Health Check returns with success. However, in many cases, if our application fails ten times but suddenly responds OK only within two requests, it’s a desire to replace that instance. But, that will not happen with the configuration above.
Also, if we allow our application to fail ten times, and on the last attempt (9), it receives an HTTP 200, it means we need to wait for another round of 10 failures to replace the instance. It isn’t evident, but I hope that you got the idea.
Application Health Check – Define Metrics
Decide the correct values for Health Check metrics. It’s not an easy process and isn’t equal for all applications. For new applications, we have to take notes from several tests and make some averages between our tests. Usually, we reproduce a high traffic volume or memory overflow that makes the application stops responding to see the behavior that those metrics will perform.