Amazon Bedrock vs Azure AI Foundry vs Google Vertex AI: 2026 Deep Comparison

The cloud AI platform landscape in 2026 looks nothing like it did even twelve months ago. Amazon Bedrock, Azure AI Foundry, and Google Vertex AI have each matured from “model hosting services” into full-stack AI development platforms complete with agent orchestration, retrieval-augmented generation pipelines, fine-tuning workflows, and enterprise-grade compliance controls. If you are a solutions architect or CTO trying to decide where to place your organization’s AI bet, the sheer volume of overlapping features makes an honest comparison difficult — and the stakes of getting it wrong are measured in seven-figure infrastructure bills.
Choosing the wrong platform costs you more than money. You lock your team into a SDK ecosystem, a compliance boundary, and a set of model exclusivity constraints that take 6 to 12 months to unwind. Meanwhile your competitors who picked correctly are shipping agents that reason over proprietary data while you are still migrating vector embeddings between cloud providers. This is not a decision you want to make twice.
This post gives you a side-by-side, no-marketing-fluff comparison of all three platforms across twelve dimensions: model catalog, agent capabilities, pricing, compliance, fine-tuning, RAG pipelines, inference options, developer experience, and more. Every number cited is based on publicly available pricing pages and service documentation as of April 2026. Where a feature is in preview or region-limited, I say so explicitly.
Platform Overview
Let me walk you through what each platform is actually built for before we get into the feature-by-feature breakdown. The origins of these three services matter a lot — they’re the reason Bedrock, AI Foundry, and Vertex AI each shine in very different use cases.
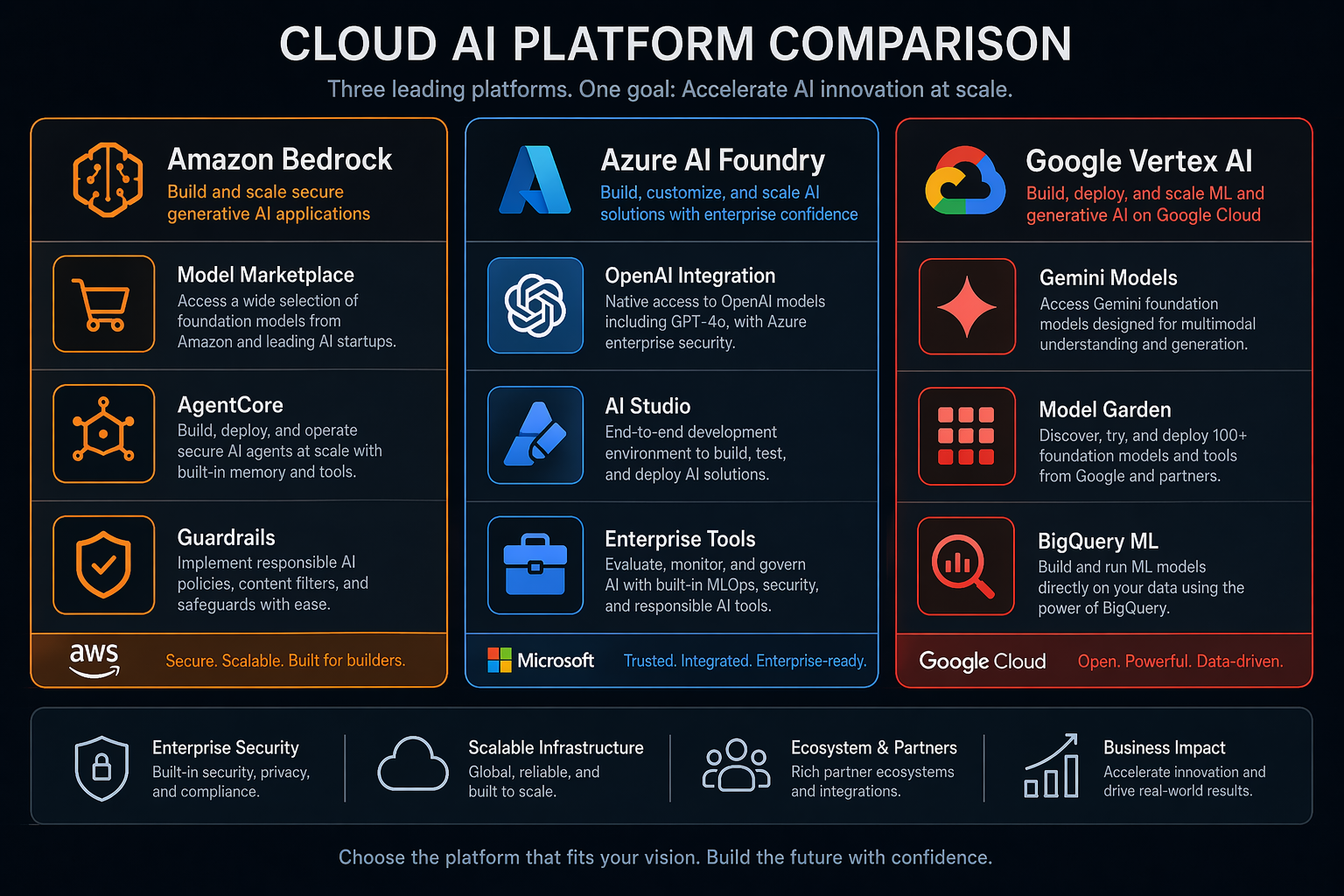
Amazon Bedrock launched in April 2023 as a model marketplace, giving AWS customers API access to foundation models from Anthropic, Meta, Mistral, Cohere, and Amazon’s own Nova family without managing infrastructure. By 2026 it has grown into a comprehensive AI platform with Bedrock AgentCore for agentic workflows, Guardrails for content filtering, Knowledge Bases for RAG, and provisioned throughput for latency-sensitive workloads. Bedrock’s core identity remains “bring your own model” — it is the only platform where you can run Claude, Llama, Mistral, and Nova behind a single API endpoint.
Azure AI Foundry is Microsoft’s rebranded and expanded AI platform (formerly Azure AI Services). Its distinguishing feature is the deep integration with OpenAI: Azure OpenAI Service gives you GPT-4o, o3, and o4-mini behind Azure’s enterprise compliance boundary, and no other cloud provider offers this. AI Foundry adds Azure AI Studio for prompt engineering, the Azure AI Agents service for building autonomous agents, and tight integration with the broader Microsoft ecosystem — Copilot Studio, Microsoft Fabric, Power Platform, and Entra ID. If your organization runs on Microsoft 365, this is the path of least resistance.
Google Vertex AI is the oldest of the three, having launched in May 2020 as a unified ML platform. Google’s advantage is its vertical integration: Gemini 2.5 Pro and Gemini 2.5 Flash are first-party models, and Google controls the full stack from TPU hardware to model weights to serving infrastructure. Model Garden provides access to third-party models (including Anthropic’s Claude via a partnership), and the Agent Builder service (powered by Google’s Vertex AI Agent Development Kit) handles agentic workflows. Google’s DNA is research-first — if your team publishes papers or needs cutting-edge multimodal capabilities, Vertex AI often ships features weeks before the competition.
| Attribute | Amazon Bedrock | Azure AI Foundry | Google Vertex AI |
|---|---|---|---|
| General Availability | April 2023 (GA Sep 2023) | Nov 2023 (rebranded Apr 2025) | May 2020 |
| Region Availability | 17 regions (6 continents) | 14 regions | 22 regions |
| FedRAMP Authorized | Yes (East/West) | Yes (Azure Government) | Yes (GovCloud) |
| HIPAA BAA | Yes | Yes | Yes |
| SOC 2 Type II | Yes | Yes | Yes |
| ISO 27001 | Yes | Yes | Yes |
| Free Tier | Limited (3 months trial) | Yes ($200/month Azure credit) | Yes ($300/month Google credit) |
| Primary Differentiator | Model marketplace breadth | OpenAI exclusivity | Gemini + TPU vertical stack |
Model Catalog Comparison
The single most important decision factor for many teams is: which models can I actually use? The answer varies more than you might expect.
Amazon Bedrock offers the broadest model catalog in 2026 with over 40 foundation models from eight providers. The standouts are Claude 4 Sonnet and Opus from Anthropic (Bedrock is the only non-Anthropic API that offers Claude with enterprise indemnification), Llama 4 Maverick and Scout from Meta, Mistral Large 3, Nova Pro and Nova Premier from Amazon, and Command R+ from Cohere. Bedrock also hosts Stable Diffusion 4 and Titan Image Generator for image generation, plus Titan and Cohere embedding models.
Azure AI Foundry centers on the OpenAI partnership. You get GPT-4o, GPT-4.1, o3, and o4-mini exclusively through Azure OpenAI Service — neither AWS nor Google Cloud offers these models. Azure also provides access to Phi-4 (Microsoft’s small language model family), Llama 4 via the Model-as-a-Service catalog, Mistral Large 3, and Cohere Command R+. For image generation, DALL-E 4 is exclusive to Azure. The gap is Anthropic: Claude is not available on Azure AI Foundry as of April 2026.
Google Vertex AI leads with its own Gemini 2.5 Pro and Gemini 2.5 Flash models, which consistently benchmark at or near the top of LMSYS Chatbot Arena for multimodal tasks. Through Model Garden you also get access to Claude 4 Sonnet (via Anthropic’s Google Cloud partnership), Llama 4, Mistral Large 3, and Gemma 3 (Google’s open-weight model family). Imagen 4 handles image generation, and Google’s Chirp 3 serves speech-to-text and text-to-speech. The notable absence: no OpenAI models.
| Model Family | Amazon Bedrock | Azure AI Foundry | Google Vertex AI |
|---|---|---|---|
| Claude 4 (Anthropic) | Sonnet, Opus | Not available | Sonnet only |
| GPT-4o / o3 / o4 (OpenAI) | Not available | Full access | Not available |
| Gemini 2.5 Pro/Flash | Not available | Not available | Full access |
| Llama 4 (Meta) | Maverick, Scout | Maverick, Scout | Maverick, Scout |
| Mistral Large 3 | Yes | Yes | Yes |
| Nova (Amazon) | Pro, Premier, Lite, Micro | Not available | Not available |
| Phi-4 (Microsoft) | Not available | Yes (all variants) | Not available |
| Cohere Command R+ | Yes | Yes | Yes |
| Gemma 3 (Google) | Not available | Not available | Full access |
| Stable Diffusion 4 / Imagen 4 | SD4 + Titan | DALL-E 4 | Imagen 4 |
| Embedding Models | Titan, Cohere | Ada-003, Phi-embed | Gecko, PaLM-embed |
The key takeaway: no single platform gives you access to every major model family. If you need Claude and GPT in the same application, you will need a multi-cloud strategy or a third-party router like LiteLLM. If you are standardizing on a single provider, your model choice effectively dictates your cloud platform.
Agent Capabilities
Agentic AI is the battleground where all three platforms are investing the most engineering effort in 2026. Each has taken a fundamentally different architectural approach.
Amazon Bedrock AgentCore is the most opinionated agent framework of the three. You define an agent by specifying a foundation model, a set of Action Groups (Lambda functions that the agent can invoke), and optional Knowledge Bases for RAG. AgentCore handles orchestration, planning, and tool invocation automatically. The 2026 release added multi-agent collaboration (agents can delegate sub-tasks to other agents), session memory backed by DynamoDB, and trace-level observability through CloudWatch. Bedrock Agents vs Nova Pro is a common architectural decision — Nova Pro with its native tool-use capability can replace simple agents entirely, reducing latency and cost. Guardrails can be attached at the agent level to block harmful outputs or prevent data exfiltration.
Azure AI Agents (formerly Azure OpenAI Assistants) leans on the OpenAI Agents SDK and integrates natively with the Microsoft ecosystem. Agents can call Azure Functions, connect to SharePoint and Teams via Microsoft Graph, and authenticate users through Entra ID. The tool-use framework supports function calling, code interpreter (sandboxed Python execution), and file search with vector stores. Memory is managed through thread objects that persist conversation history. The 2026 updates added multi-agent orchestration through the Semantic Kernel framework and content filters that apply at both the model and agent level.
Google Vertex AI Agent Builder is the most flexible but also the most hands-on option. You build agents using the Agent Development Kit (ADK), which supports both code-first (Python) and declarative (YAML) agent definitions. Agent Builder integrates with Vertex AI Search for grounding, Cloud Functions or Cloud Run for tool execution, and AlloyDB or Memorystore for state persistence. Google’s unique advantage is grounding with Google Search, which gives agents access to real-time web information with citation support. The 2026 release introduced A2A protocol (agent-to-agent communication) and multi-agent orchestration patterns.
| Agent Feature | Bedrock AgentCore | Azure AI Agents | Vertex AI Agent Builder |
|---|---|---|---|
| Tool Use | Lambda, API (OpenAPI schema) | Azure Functions, Graph, Code Interpreter | Cloud Functions, Cloud Run, API |
| Memory | DynamoDB-backed sessions | Thread objects (Cosmos DB) | AlloyDB / Memorystore |
| Multi-Agent | Yes (collaborative) | Yes (Semantic Kernel) | Yes (A2A protocol) |
| Observability | CloudWatch traces | Azure Monitor, Application Insights | Cloud Trace, Cloud Logging |
| Guardrails | Bedrock Guardrails | Content filters (model + agent level) | Safety settings, data loss prevention |
| Grounding | Knowledge Bases (OpenSearch, Pinecone) | Azure AI Search | Vertex AI Search + Google Search |
| Orchestration | Automatic (planning chain) | Automatic + Semantic Kernel | Code-first or declarative |
| IDE Integration | AWS Toolkit (VS Code, JetBrains) | AI Studio + VS Code | Vertex AI Studio + VS Code |
| Max Agent Steps | 25 (configurable) | 128 (configurable) | 50 (configurable) |
For teams building production agents, the choice often comes down to your existing cloud stack. Bedrock AgentCore is the best fit for AWS-native organizations. Azure AI Agents wins if you need deep Microsoft 365 integration. Vertex AI Agent Builder is the right call if you want maximum control over the agent loop and need Google Search grounding.
Pricing Comparison
Pricing is where the three platforms diverge most sharply. Each uses a different unit of measurement and pricing model, making direct comparison harder than it should be. The tables below normalize pricing to per-million-token rates as of April 2026.
Amazon Bedrock uses an on-demand pricing model with per-token billing. You pay for what you consume with no minimum commitment. Provisioned throughput is available for latency-sensitive workloads at a fixed hourly rate with model-specific throughput units. Bedrock also offers Model Evaluation jobs (billed per job) and Custom Model hosting (billed per inference).
Azure AI Foundry prices OpenAI models identically to OpenAI’s direct API but adds Azure’s enterprise SLA. Pay-as-you-go is the default, and Provisioned Throughput Units (PTUs) are available for guaranteed capacity. Non-OpenAI models (Llama, Mistral, Phi) follow standard Azure ML pricing. Azure also charges separately for AI Search instances, which most RAG architectures require.
Google Vertex AI offers the most flexible pricing with three modes: pay-per-use (on-demand), committed use discounts (1-year or 3-year contracts with up to 57% savings), and Provisioned Throughput for Gemini models. Google also offers context caching for Gemini models at a 75% discount on cached input tokens, which is a significant cost saver for agentic workflows with long system prompts.
| Model | Platform | Input (per 1M tokens) | Output (per 1M tokens) |
|---|---|---|---|
| Claude 4 Sonnet | Bedrock | $3.00 | $15.00 |
| Claude 4 Sonnet | Vertex AI | $3.00 | $15.00 |
| Claude 4 Opus | Bedrock | $15.00 | $75.00 |
| GPT-4o | Azure AI Foundry | $2.50 | $10.00 |
| GPT-4.1 | Azure AI Foundry | $2.00 | $8.00 |
| o3 | Azure AI Foundry | $10.00 | $40.00 |
| o4-mini | Azure AI Foundry | $1.10 | $4.40 |
| Gemini 2.5 Pro | Vertex AI | $1.25 | $10.00 |
| Gemini 2.5 Pro (cached) | Vertex AI | $0.31 | $10.00 |
| Gemini 2.5 Flash | Vertex AI | $0.15 | $0.60 |
| Llama 4 Maverick | Bedrock | $0.55 | $0.55 |
| Llama 4 Maverick | Azure AI Foundry | $0.65 | $0.65 |
| Llama 4 Maverick | Vertex AI | $0.50 | $0.50 |
| Mistral Large 3 | Bedrock | $2.00 | $6.00 |
| Mistral Large 3 | Azure AI Foundry | $2.00 | $6.00 |
| Nova Pro | Bedrock | $0.80 | $3.20 |
| Nova Premier | Bedrock | $4.00 | $16.00 |
| Phi-4 Mini | Azure AI Foundry | $0.10 | $0.40 |
| Cohere Command R+ | Bedrock | $2.50 | $10.00 |
| Service Type | Amazon Bedrock | Azure AI Foundry | Google Vertex AI |
|---|---|---|---|
| Image Generation | $0.040/image (Titan) | $0.040/image (DALL-E 4) | $0.030/image (Imagen 4) |
| Embeddings (per 1M tokens) | $0.02 (Titan) | $0.02 (Ada-003) | $0.02 (Gecko) |
| Fine-Tuning (per 1M tokens) | Varies by model | Varies by model | Varies by model |
| Provisioned Throughput | From $0.896/hr (Nova Lite) | From $1.20/hr (GPT-4o-mini) | Contact sales (Gemini) |
| Batch API | 50% discount | 50% discount | 50% discount |
| Context Caching | Not available | Not available | 75% discount (Gemini) |
| Data Transfer In | Free | Free | Free |
| Data Transfer Out | $0.09/GB (first 10TB) | $0.087/GB (first 10TB) | $0.12/GB (first 10TB) |
A critical cost factor that many architectures overlook is Bedrock cost attribution. Bedrock supports granular cost allocation tags at the agent and model level, which is essential for enterprises running dozens of AI workloads. Azure provides similar cost management through Cost Management + Billing with resource group-level tagging. Google’s billing labels work at the project and resource level but lack the agent-level granularity of Bedrock.
For high-volume inference (over 500 million tokens per month), provisioned throughput becomes the dominant cost lever. Google’s committed use discounts offer the steepest savings at 57% for 3-year commitments, but you are locking in a specific model family. Bedrock’s provisioned throughput is model-agnostic within a provider family, giving you more flexibility. Azure PTUs are locked to specific OpenAI model versions.
Compliance and Security
For regulated industries — healthcare, financial services, government — compliance posture is not a nice-to-have, it is a hard requirement. Each platform has invested heavily, but the specifics matter.
Amazon Bedrock runs within your AWS VPC and supports AWS PrivateLink for private connectivity. Data processed by Bedrock is never used to train the underlying foundation models (contractually guaranteed for all providers except Amazon’s own Nova models, which use a separate opt-in training pipeline). Bedrock is FedRAMP High authorized in AWS GovCloud (US-East, US-West), holds HIPAA BAA, SOC 2 Type II, ISO 27001, ISO 27017, ISO 27018, and is in scope for PCI DSS. Data residency controls let you restrict model inference to specific regions, and all data is encrypted at rest (AES-256) and in transit (TLS 1.2+). The Bedrock Guardrails service provides configurable content filtering with up to 99% harmful content rejection rates based on AWS benchmarks.
Azure AI Foundry inherits Microsoft’s massive compliance portfolio — the widest of the three platforms by a significant margin. Azure holds over 100 compliance certifications including FedRAMP High, HIPAA, HITRUST, SOC 1/2/3, ISO 27001/27017/27018, PCI DSS Level 1, and industry-specific certifications like FFIEC (financial services) and FedRAMP IL5 (defense). Azure OpenAI Service supports customer-managed keys (CMK) through Azure Key Vault, private endpoints for network isolation, and data loss prevention (DLP) policies through Microsoft Purview. Content safety filters are enabled by default and cannot be fully disabled — a design choice that some teams find restrictive but that dramatically reduces compliance risk. Data processed by Azure OpenAI is not used for training, with contractual guarantees.
Google Vertex AI benefits from Google’s long history of running security-first cloud infrastructure. Vertex AI is FedRAMP High authorized (Google Cloud for Government), HIPAA compliant, SOC 2 Type II certified, and holds ISO 27001/27017/27018 certifications. Google’s Confidential Computing option lets you encrypt data in use — something neither AWS nor Azure currently offers for AI inference workloads. VPC Service Controls provide network-level isolation for Vertex AI resources, and Customer-Managed Encryption Keys (CMEK) through Cloud KMS give you control over data encryption. Google’s data processing addendum contractually prohibits using customer data for model training across all Vertex AI models, including Google’s own Gemini family.
| Compliance Feature | Amazon Bedrock | Azure AI Foundry | Google Vertex AI |
|---|---|---|---|
| FedRAMP High | Yes (GovCloud) | Yes (Azure Government) | Yes (Google Cloud Gov) |
| HIPAA BAA | Yes | Yes | Yes |
| SOC 2 Type II | Yes | Yes | Yes |
| ISO 27001 | Yes | Yes | Yes |
| PCI DSS | In scope | Level 1 | In scope |
| GDPR | Yes | Yes | Yes |
| Data Residency Controls | Region-level | Region-level | Region + org policy |
| Private Endpoints | PrivateLink | Private Endpoints | VPC Service Controls |
| Customer-Managed Keys | Yes (KMS) | Yes (Key Vault) | Yes (Cloud KMS) |
| Confidential Computing | Not available | Not available | Yes (Gemini) |
| Content Filtering | Guardrails (configurable) | Content filters (mandatory minimum) | Safety settings (configurable) |
| Data Used for Training | No (contractual) | No (contractual) | No (contractual) |
| Audit Logging | CloudTrail | Azure Monitor + Log Analytics | Cloud Audit Logs |
If compliance breadth is your primary criterion, Azure AI Foundry wins on sheer certification count. If you need confidential computing for highly sensitive inference workloads, Vertex AI is the only option. If you want the most flexible content filtering configuration (or need to disable filtering for specific use cases), Bedrock gives you the most control.
Fine-Tuning and Customization
Off-the-shelf foundation models get you 80% of the way there. The last 20% — domain-specific accuracy, brand voice adherence, specialized task performance — requires fine-tuning. Each platform approaches this differently.
Amazon Bedrock supports custom model fine-tuning for Claude (Sonnet variants), Llama 4, Mistral, and Nova models using LoRA (Low-Rank Adaptation) and QLoRA techniques. You upload a JSONL training dataset to S3, select a base model, choose hyperparameters (or accept defaults), and Bedrock manages the training infrastructure. Fine-tuned models are billed at the same per-token rate as the base model plus a one-time training cost (billed per training hour). Bedrock also supports custom model import — you can bring a model fine-tuned externally (on SageMaker or elsewhere) and deploy it behind the Bedrock inference API. Model evaluation jobs let you compare base and fine-tuned models on custom benchmarks using automatic metrics (accuracy, F1, ROUGE) or human evaluation through a managed UI.
Azure AI Foundry provides fine-tuning for GPT-4o-mini, GPT-4.1-mini, Phi-4, and Llama 4 through Azure AI Studio’s guided fine-tuning workflow. The process supports supervised fine-tuning with JSONL datasets and preference optimization (DPO) for alignment. Azure’s unique advantage is evaluation and red-teaming tools built into AI Studio — you can run safety evaluations, groundedness checks, and custom metrics against your fine-tuned model before deploying it. Fine-tuned OpenAI models are deployed as custom endpoints with dedicated capacity. Azure also supports model distillation (transferring knowledge from a larger model to a smaller one) for Phi-4 variants.
Google Vertex AI offers the most comprehensive fine-tuning toolkit. For Gemini models, you can fine-tune using supervised tuning with as few as 100 examples, or use reinforcement learning from human feedback (RLHF) for alignment tuning. The Model Registry manages versioned fine-tuned models alongside base models. Vertex AI supports LoRA, QLoRA, and full-parameter fine-tuning for open-source models deployed on Vertex. The Pipeline feature lets you build end-to-end fine-tuning workflows with custom preprocessing, training, evaluation, and deployment stages using Kubeflow Pipelines or the Vertex AI Pipelines SDK. Google also offers distillation for Gemini models and model armor for safety evaluation.
| Fine-Tuning Feature | Amazon Bedrock | Azure AI Foundry | Google Vertex AI |
|---|---|---|---|
| LoRA Support | Claude, Llama, Mistral, Nova | GPT-4o-mini, Phi-4, Llama | Gemini, Llama, Gemma |
| QLoRA Support | Yes (Llama, Mistral) | Yes (Llama) | Yes (Llama, Gemma) |
| Full-Parameter Tuning | Not available | Not available | Yes (open models) |
| RLHF | Not available | DPO only | Yes (Gemini) |
| Custom Model Import | Yes (SageMaker, custom) | Yes (custom containers) | Yes (custom containers) |
| Distillation | Not available | Yes (Phi-4) | Yes (Gemini) |
| Min Training Examples | 100-500 | 50-100 | 20-100 |
| Training Cost | Per training hour | Per training hour | Per training node-hour |
| Eval Tools | Bedrock Model Evaluation | AI Studio Evaluation | Vertex AI Model Evaluation |
| Safety Evaluation | Via Guardrails | Built-in red-teaming | Model Armor |
For teams that need deep customization and full-parameter tuning, Vertex AI has no peer. If you want the simplest fine-tuning experience with built-in safety guardrails, Azure AI Studio’s guided workflow is the most approachable. Bedrock’s custom model import feature is the best fit if you are already training models on SageMaker and want to serve them through the Bedrock API.
RAG and Knowledge Bases
Retrieval-Augmented Generation is the architectural pattern that makes AI useful in enterprise settings. Without RAG, your models generate plausible-sounding nonsense about your proprietary data. Each platform has invested heavily in managed RAG pipelines.
Amazon Bedrock Knowledge Bases give you a fully managed RAG pipeline. You connect an S3 data source, select an embedding model (Titan or Cohere), choose a vector store (OpenSearch Serverless, Pinecone, Redis Enterprise Cloud, or MongoDB Atlas), and Bedrock handles document chunking, embedding generation, ingestion, and retrieval. The 2026 release added support for web crawler connectors (ingesting public websites), Confluence and SharePoint connectors for enterprise knowledge, and hybrid search combining semantic and keyword retrieval. Chunking strategies include fixed-size, hierarchical, and semantic chunking with configurable overlap. Hybrid RAG on AWS is a well-documented pattern that combines OpenSearch keyword search with Bedrock semantic retrieval for significantly better relevance than either approach alone.
Azure AI Foundry approaches RAG through Azure AI Search (formerly Cognitive Search) combined with OpenAI embedding models. Azure AI Search is a mature, feature-rich search engine that predates the generative AI wave — it supports full-text search, vector search, hybrid search, semantic ranking, and custom analyzers in 56 languages. The tight integration between Azure OpenAI Service and AI Search means you can build RAG pipelines entirely within AI Studio’s visual designer without writing code. Azure also supports Grounding with Bing for augmenting responses with real-time web data, and Semantic Kernel provides an orchestration layer for complex multi-step retrieval pipelines.
Google Vertex AI Search (formerly Enterprise Search on Generative AI App Builder) offers the most integrated RAG experience. You point it at a data source — Google Cloud Storage, BigQuery, websites, or third-party connectors (Salesforce, Jira, Confluence, Slack) — and it automatically handles chunking, embedding, indexing, and retrieval using Gemini’s native multimodal understanding. Google’s unique advantage is that Vertex AI Search can ground responses in both your proprietary data and Google Search results simultaneously, providing citations for both. The ranker uses Gemini to re-rank retrieved passages for relevance, which Google benchmarks show improves retrieval accuracy by 15-20% over traditional semantic search. Vector search is powered by Google’s ScaNN algorithm, which is optimized for low-latency approximate nearest neighbor queries at billion-vector scale.
| RAG Feature | Bedrock Knowledge Bases | Azure AI Search + OpenAI | Vertex AI Search |
|---|---|---|---|
| Vector Store Options | OpenSearch, Pinecone, Redis, MongoDB | Native (Azure AI Search) | Native (Vertex AI) |
| Hybrid Search | Yes (semantic + keyword) | Yes (full-text + vector) | Yes (semantic + keyword) |
| Chunking Strategies | Fixed, hierarchical, semantic | Fixed, custom skill pipeline | Automatic (learned) |
| Embedding Models | Titan, Cohere | Ada-003, Phi-embed | Gecko, Gemini native |
| Data Connectors | S3, web, Confluence, SharePoint | Blob, ADLS, SharePoint, 90+ connectors | GCS, BigQuery, 100+ connectors |
| Web Grounding | Via web crawler ingestion | Bing grounding | Google Search grounding |
| Re-Ranking | Not built-in (custom Lambda) | Semantic ranker (built-in) | Gemini ranker (built-in) |
| Max Index Size | Dependent on vector store | 25M documents per index | 100M+ documents |
| Multimodal Retrieval | Image embeddings (Titan) | Image vectors (custom) | Native (Gemini multimodal) |
| Incremental Sync | Yes (event-driven) | Yes (indexers) | Yes (connectors) |
If you are already invested in OpenSearch or want the flexibility to choose your own vector store, Bedrock Knowledge Bases is the most flexible. If you need the most mature search engine with the broadest connector ecosystem, Azure AI Search wins. If you want the simplest setup with the best out-of-the-box retrieval quality, Vertex AI Search is the fastest path to production.
Inference Options
Production AI workloads have wildly different latency, throughput, and cost requirements. A customer-facing chatbot needs sub-second response times. A document summarization pipeline can tolerate minutes. A batch classification job can run overnight. Each platform offers multiple inference modes to address these needs.
Amazon Bedrock provides three inference modes. On-demand inference is the default — you pay per token with no capacity guarantees. Provisioned throughput reserves model capacity for a fixed hourly rate, guaranteeing latency SLAs (typically p99 under 500ms for Nova models). Batch inference processes large datasets asynchronously with a 50% cost discount and a 24-hour turnaround SLA. The 2026 addition of prompt routing (in preview) automatically directs requests to the most cost-effective model that can satisfy your quality requirements based on prompt complexity. Bedrock also supports model distillation in preview, letting you compress a larger teacher model into a smaller student model that runs faster and cheaper.
Azure AI Foundry offers similar patterns. Pay-as-you-go inference is the default for Azure OpenAI Service. Provisioned Throughput Units (PTUs) reserve capacity for GPT-4o and GPT-4.1 deployments with guaranteed throughput and latency. Global Standard deployments route requests to the nearest Azure region with available capacity, which can reduce latency for geographically distributed applications. Batch processing via the Batch API provides 50% cost savings with a 24-hour SLA. Azure’s model distillation feature (GA in 2026) lets you fine-tune smaller Phi-4 models using outputs from larger GPT-4o models, creating lightweight models that retain most of the teacher’s quality at a fraction of the cost.
Google Vertex AI has the most inference options. Online prediction serves real-time requests with per-token billing. Batch prediction processes large datasets at 50% discount. Provisioned throughput for Gemini models guarantees capacity and latency. Google’s standout feature is context caching for Gemini models — you cache long system prompts or document contexts and pay 75% less for subsequent requests that reuse the cached context. For agentic workflows that repeatedly pass the same system instructions, this reduces input token costs dramatically. Vertex AI Predict also supports A/B testing different model versions simultaneously and traffic splitting for gradual model rollouts.
| Inference Feature | Amazon Bedrock | Azure AI Foundry | Google Vertex AI |
|---|---|---|---|
| On-Demand Inference | Yes | Yes | Yes |
| Provisioned Throughput | Yes (all models) | Yes (OpenAI models) | Yes (Gemini models) |
| Batch Processing | Yes (50% discount) | Yes (50% discount) | Yes (50% discount) |
| Context Caching | Not available | Not available | Yes (75% discount) |
| Prompt Routing | Preview | Not available | Not available |
| Model Distillation | Preview | GA (GPT to Phi) | GA (Gemini to Gemma) |
| A/B Testing | Custom (via route53) | Traffic splitting | Built-in |
| Global Routing | Cross-region inference | Global Standard | Global endpoint |
| Latency SLA | p99 < 500ms (provisioned) | p99 < 600ms (PTU) | p99 < 400ms (provisioned) |
| Max Context Window | 200K (Claude), 1M (Nova) | 128K (GPT-4o), 1M (o3) | 1M (Gemini 2.5 Pro) |
Google’s context caching is the single biggest cost optimization feature across all three platforms for agentic workloads. If your architecture involves repeatedly sending the same context (system prompts, tool definitions, knowledge base documents), Vertex AI can cut your input token costs by 75%.
Developer Experience
The quality of SDKs, documentation, and tooling directly impacts how quickly your team can ship. A platform with 40 models but poor documentation is less useful than one with 10 models and excellent developer ergonomics.
Amazon Bedrock uses the standard AWS SDK (boto3 for Python, AWS SDK for Java, JavaScript, Go, .NET). The Bedrock API follows AWS conventions — you construct requests with model IDs, content arrays, and inference configurations. Documentation is thorough but follows AWS’s characteristic style: comprehensive reference docs with fewer guided tutorials. The Bedrock console provides a playground for testing models, a visual agent builder, and monitoring dashboards. AWS CloudFormation and Terraform support is available for infrastructure-as-code deployments. The learning curve is steeper if your team is not already familiar with AWS SDK patterns.
Azure AI Foundry shines in developer experience, particularly for teams already in the Microsoft ecosystem. The Azure AI Studio is a web-based IDE that combines prompt engineering, agent building, evaluation, and deployment in a single interface. The Azure OpenAI SDK is a thin wrapper around the OpenAI SDK — if you have existing OpenAI integration code, migrating to Azure OpenAI typically requires changing only the base URL and authentication method. Semantic Kernel is Microsoft’s open-source orchestration SDK that provides a high-level abstraction for building AI applications with planners, memory, and connectors. Documentation is excellent with extensive quickstarts and sample applications. GitHub Copilot integration means your developers can interact with Azure AI models directly from VS Code.
Google Vertex AI provides the Vertex AI SDK for Python (built on the Google Cloud client libraries) and the Generative AI SDK (a simpler, OpenAI-compatible interface for Gemini models). Vertex AI Studio is a web-based notebook environment for prototyping prompts and comparing model outputs. Google’s documentation quality has improved significantly in 2026, with comprehensive guides and Colab notebooks for common tasks. The ADK (Agent Development Kit) provides a clean Python API for building agents. Where Vertex AI falls short is IDE integration — there is no first-party VS Code extension comparable to Azure’s tooling, and the Terraform provider for Vertex AI resources is less mature than its AWS or Azure equivalents.
| DX Feature | Amazon Bedrock | Azure AI Foundry | Google Vertex AI |
|---|---|---|---|
| Primary SDK | AWS SDK (boto3, etc.) | Azure OpenAI SDK + Semantic Kernel | Vertex AI SDK + Gen AI SDK |
| OpenAI-Compatible API | Not available | Yes (Azure OpenAI) | Yes (limited, for Gemini) |
| Visual Builder | Bedrock console | AI Studio | Vertex AI Studio |
| Infrastructure as Code | CloudFormation, Terraform | Bicep, ARM, Terraform | Terraform (limited), Pulumi |
| Sample Code Library | Extensive (GitHub) | Extensive (GitHub + Learn) | Good (GitHub + Colab) |
| CLI Tool | AWS CLI | Azure CLI + az ml | gcloud CLI |
| Playground | Console playground | AI Studio playground | Vertex AI Studio |
| Local Development | SAM, CDK | Azure ML workspaces | Vertex AI Workbench |
If your team is already writing OpenAI-compatible code and wants the fastest migration path, Azure AI Foundry is the clear winner. If you want the most opinionated, production-ready orchestration framework, Semantic Kernel gives Azure a significant edge. For teams that prefer code-first, notebook-driven development, Vertex AI’s Colab integration is hard to beat.
Decision Matrix
The table below scores each platform on a 1-5 scale across eight dimensions. These scores reflect a weighted assessment based on typical enterprise requirements in 2026.
| Dimension | Amazon Bedrock | Azure AI Foundry | Google Vertex AI |
|---|---|---|---|
| Model Variety | 5 | 3 | 4 |
| Agent Capabilities | 4 | 4 | 4 |
| Cost Competitiveness | 4 | 3 | 5 |
| Compliance Breadth | 4 | 5 | 4 |
| Developer Experience | 3 | 5 | 4 |
| RAG Pipeline Quality | 4 | 4 | 5 |
| Fine-Tuning Depth | 3 | 4 | 5 |
| Ecosystem Maturity | 5 | 5 | 4 |
| Total (out of 40) | 32 | 33 | 35 |
These scores are directional, not absolute. Your specific requirements will shift the weighting. A healthcare company should weight compliance at 2x, which favors Azure. A startup should weight cost at 2x, which favors Google. A company building multi-model applications should weight model variety at 2x, which favors Bedrock.
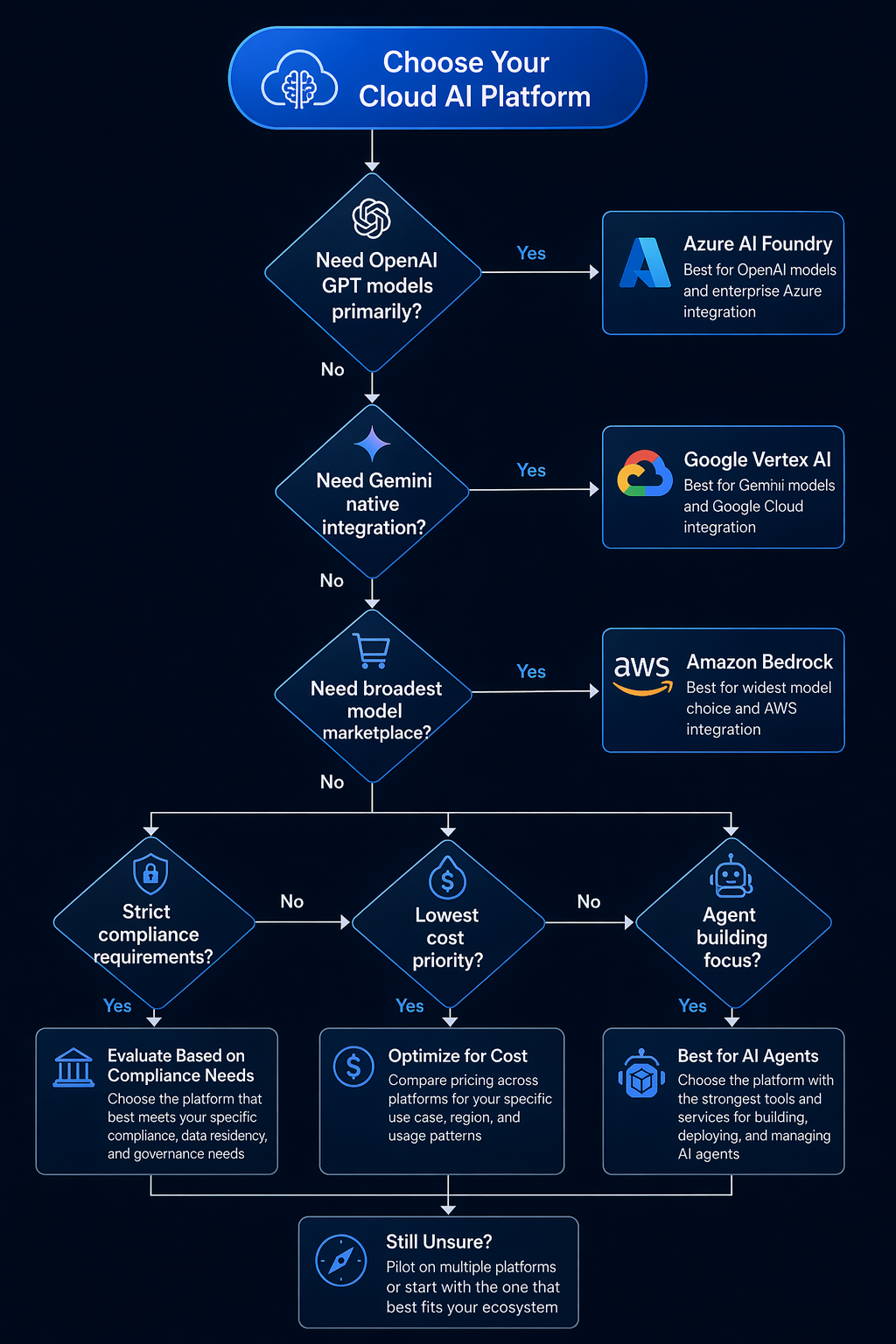
Which Platform Should You Choose
Scenario 1: Early-Stage Startup (Under 50 People)
Recommendation: Google Vertex AI
Startups should optimize for two things: minimizing burn rate and shipping fast. Vertex AI wins on both. The $300/month Google Cloud credit (for 90 days, renewable) gives you a meaningful runway for experimentation. Gemini 2.5 Flash at $0.15 per million input tokens is the cheapest high-quality model on any platform. Context caching at 75% discount means your agentic prototypes cost a fraction of what they would on Azure or AWS.
The Vertex AI SDK is clean and Pythonic, and Colab notebooks let your engineers prototype without setting up any local infrastructure. Google’s serverless inference means you never pay for idle capacity. The trade-off is that you are betting on Gemini as your primary model — if you later need GPT-4o or Claude exclusively, you will need to add a second provider. But for an early-stage company, the cost savings are worth the lock-in risk.
Scenario 2: Large Enterprise (1,000+ Employees, Regulated Industry)
Recommendation: Azure AI Foundry
If your organization runs Active Directory, Microsoft 365, and has a compliance department that sends you audit spreadsheets weekly, Azure AI Foundry is the pragmatic choice. The integration with Entra ID means your AI applications inherit existing identity and access management policies. Microsoft Purview adds data loss prevention for AI-generated content. The 100+ compliance certifications cover every regulated industry from healthcare (HIPAA, HITRUST) to financial services (FFIEC, SOC 1/2/3) to government (FedRAMP High, IL5).
The OpenAI exclusivity is the other decisive factor. If your organization has standardized on GPT models — and most enterprises have, given OpenAI’s mindshare — Azure is the only way to run GPT-4o, o3, and o4-mini within your compliance boundary. The 50% batch discount and PTU pricing keep costs manageable at scale. Semantic Kernel gives your development team a structured framework for building production agents without reinventing orchestration patterns.
For protecting your AI endpoints, consider combining Azure AI Foundry with AWS WAF if you operate in a multi-cloud environment — cross-cloud security layers are increasingly common in enterprise architectures.
Scenario 3: Research Lab or AI-Native Company
Recommendation: Amazon Bedrock
What I’ve noticed about teams that live and breathe model R&D is that they don’t just want to consume models — they want to experiment with different architectures constantly. Bedrock’s model marketplace is built for exactly this kind of workflow. You can pull in Claude 4 Opus when you need deep reasoning, switch to Llama 4 Scout for batch runs, tap Nova Pro for agent loops where cost matters, and use Mistral Large 3 for anything multilingual — all without juggling separate enterprise agreements for each one.
The custom model import feature is something research teams tend to overlook until they actually need it. If you’re training models on SageMaker or working with open-source training frameworks, you train once, deploy behind the Bedrock API, and you get the same inference setup, monitoring, and guardrails as the first-party models. It’s also worth mentioning that Bedrock’s model evaluation service includes human-in-the-loop review, which is the sort of thing that sounds optional until your research lead asks for rigorous quality baselines.
The catch, of course, is cost. Bedrock’s per-token pricing usually runs about 10-20% higher than what you’d pay on Vertex AI for comparable models, and there’s no context caching to soften the blow on long-context workloads. But if your team cares more about having every model at their fingertips than shaving every last cent off the bill, nothing else really compares.
Conclusion
The honest answer to “which AI platform should I choose” is that there is no single winner. Amazon Bedrock dominates on model variety and custom model workflows. Azure AI Foundry wins on compliance breadth and OpenAI exclusivity. Google Vertex AI leads on cost optimization and fine-tuning depth.
The pattern we see in 2026 is that most serious organizations end up using two of the three platforms — a primary platform for 80% of workloads and a secondary one for specific capabilities. The most common pairing is Azure AI Foundry (for GPT models and Microsoft ecosystem integration) plus Amazon Bedrock (for Claude and the broader model catalog). Google Vertex AI tends to be either the primary platform or not used at all, because its strengths (Gemini models, context caching, fine-tuning depth) are maximized when you go all-in.
If you are making this decision today, start with your model requirements. If GPT-4o or o3 is non-negotiable, your choice is made: Azure. If Claude is your primary model, choose between Bedrock and Vertex AI based on whether you value model variety (Bedrock) or cost optimization (Vertex AI). If you want the cheapest path to production with a single strong model family, Vertex AI and Gemini is the leanest option.
The cloud AI platform market is still consolidating. Expect significant pricing changes in Q3-Q4 2026 as competition intensifies, particularly as open-source models like Llama 4 continue to close the quality gap with proprietary models. Build your architecture with an abstraction layer — whether that is LiteLLM, a custom router, or a multi-cloud agent framework — so you can shift workloads as pricing and capabilities evolve. The platform you choose today should not be a bet you cannot unwind tomorrow.
Explore more like this

Aurora Serverless v2 + Bedrock: AI Database Queries in 2026
I connected Bedrock to our Aurora cluster last month. The first thing I asked it was “show me all customers who churned in Q1 but came back in Q2” —...

AWS WAF Rules Deep Dive: Rate-Based, Geo, and Custom Rules
WAF is one of those services where the default managed rules get you 80% of the way there. The last 20% is where it gets interesting.


Comments