Copy Fail CVE-2026-31431: Patch Linux, Kubernetes Nodes, and CI Runners First

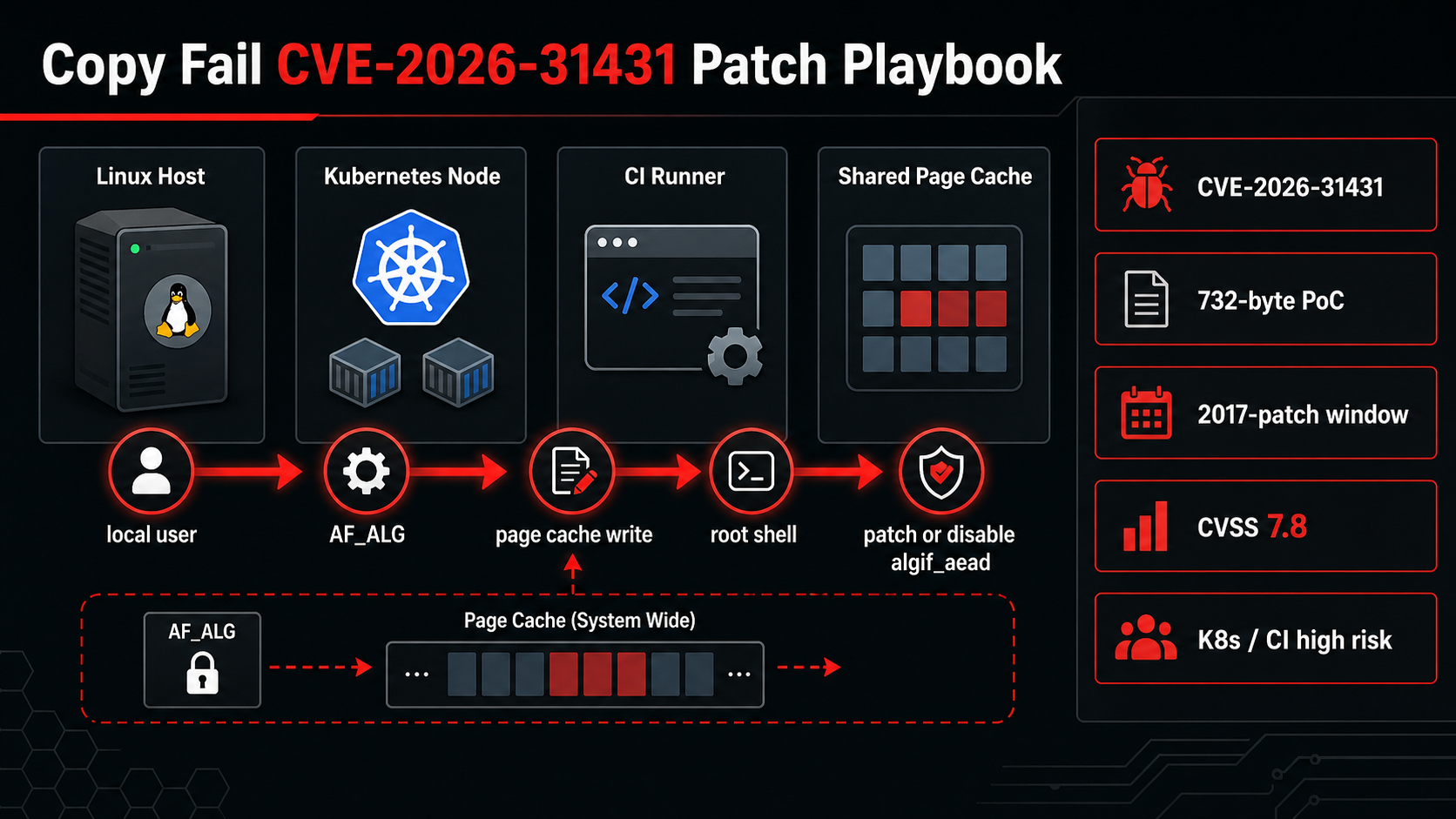
CVE-2026-31431 is not the kind of Linux bug you leave for the next maintenance window. CERT-EU says Copy Fail was publicly disclosed on April 29, 2026, has a CVSS 3.1 score of 7.8, and should be prioritized on Kubernetes nodes and CI/CD runners. That last part is the giveaway. The bug is local, but modern infrastructure turns “local user” into “any build job, container, plugin, or contractor shell that lands on the box.”
The exploit path is ugly because it is simple enough to operationalize. The vulnerable area is the Linux kernel’s algif_aead module, part of the userspace crypto API exposed through AF_ALG. CERT-EU describes a controlled 4-byte page-cache write that can target setuid binaries and end in a root shell. You do not need a dramatic remote exploit chain for that to matter. A single self-hosted runner that accepts untrusted pull requests is enough surface area.
Related 2026 update: for the adjacent operating pattern, see the BitsLovers guide to Dirty Frag and Fragnesia Linux LPE response.
What Changed
The first operational detail is the timeline. CERT-EU lists April 29 as the public disclosure date and April 30 as the advisory release date. The issue traces back to a 2017 in-place optimization in algif_aead; the upstream fix reverts that optimization and returns the operation to an out-of-place copy model. Nine years is a long time for a kernel behavior to sit under CI, bastions, developer workstations, and container hosts.
Do not read “local privilege escalation” as “low priority.” In a single-user laptop, local exploitation still hurts. On shared infrastructure, it becomes worse. A build step that should only run as an unprivileged user can become root on the host. A compromised pod with access to the right kernel interface can punch above its namespace. A short-lived debug account can stop being short-lived.
If you run EKS, self-managed Kubernetes, GitHub Actions runners, GitLab runners, Jenkins agents, or any Linux fleet where users can execute arbitrary code, put this above routine package drift.
The Numbers That Matter
| Fact | Number or date | Source |
|---|---|---|
| Public disclosure | April 29, 2026 | CERT-EU |
| Advisory release | April 30, 2026 at 09:25:30 | CERT-EU |
| Severity | CVSS 3.1 score 7.8 HIGH | NVD / kernel.org CNA |
| Primitive | controlled 4-byte write to page-cache-backed data | CERT-EU |
| High-priority targets | Kubernetes nodes and CI/CD runners | CERT-EU |
Those facts are the reason this post should be published now, not next quarter. The dates are fresh, the limits are concrete, and the operational impact is clear enough for an engineer to act on today.
How It Works in Practice
Start with asset ownership. Separate hosts into three buckets: untrusted workload hosts, semi-trusted operator hosts, and single-purpose servers. Patch the first bucket first. CI runners and Kubernetes worker nodes deserve the shortest clock because they intentionally execute code you did not hand-write.
Then check whether AF_ALG is reachable. CERT-EU recommends disabling algif_aead until vendor kernels are available. That is a mitigation, not a substitute for patching. It can affect workloads that explicitly bind crypto sockets through the kernel userspace crypto API, so test it on boxes that run IPsec-adjacent or crypto-accelerated software.
For containers, block AF_ALG socket creation with seccomp. That is the practical container control because the exploit needs to open an AF_ALG socket first. If you already maintain runtime policies from runtime container security on EKS, treat this as another reason to make those policies part of the platform baseline, not an optional hardening appendix.
uname -r
modprobe -n -v algif_aead || true
lsof 2>/dev/null | grep AF_ALG || true
# Temporary mitigation from CERT-EU. Test before broad rollout.
echo "install algif_aead /bin/false" | sudo tee /etc/modprobe.d/disable-algif.conf
sudo rmmod algif_aead 2>/dev/null || true
For Kubernetes, apply the same idea at the workload boundary. A pod that does not need kernel crypto sockets should not be allowed to create them. If your clusters still treat seccomp as a “later” control, this is the kind of CVE that turns later into now.
Gotchas I Would Check First
- A patched container image does not patch the host kernel. Node AMIs, managed node groups, and self-managed nodes need their own upgrade path.
- A disabled module can come back after reboot if the mitigation is not persisted under
/etc/modprobe.d/. - A self-hosted runner can be more exposed than a production server because it executes code from branches, forks, generated scripts, and third-party actions.
Decision Guide
| Environment | Priority | Recommended action |
|---|---|---|
| CI/CD runner accepting untrusted code | 1 | Patch or isolate immediately; apply algif_aead mitigation if patching lags |
| Kubernetes worker node | 1 | Patch node image, rotate nodes, block AF_ALG through seccomp where possible |
| Bastion or shared admin host | 2 | Patch fast; audit local users and recent shell access |
| Single-purpose private server | 3 | Patch in the normal emergency window after higher-risk hosts |
For related background, keep these existing BitsLovers posts close: runtime container security on EKS, CI/CD supply-chain incident response, Amazon Inspector vulnerability management, SBOM-driven supply-chain controls.
Sources
- CERT-EU advisory
- NVD CVE record
- Theori proof-of-concept repository
- Kubernetes seccomp tutorial
- Docker seccomp docs
The short version: patch the kernel, but do not wait quietly for every vendor package. Block the first exploit step on containers and runners while the kernel rollout catches up.
Explore more like this

AWS Lambda MicroVMs: Build a Stateful AI Code Sandbox
AWS Lambda MicroVMs gives application developers direct control of a serverless Firecracker virtual machine. That sentence needs one qualification: this is not a long-running EC2 replacement, and it is not...

AWS Security Hub MCP App: Investigate Risk from Claude Desktop
AWS released the Security Hub MCP App in public preview on July 27, 2026. It runs as a local Model Context Protocol server, uses the AWS credentials already configured on...


Comments