AWS Lambda Durable Functions vs Step Functions: The Serverless Workflow Decision Framework

AWS Lambda Durable Functions change a decision that used to be almost automatic. For years, if a serverless workflow needed to wait, retry, branch, call several services, or survive failure, the usual AWS answer was Step Functions. Now Lambda can run durable executions for up to one year, checkpoint progress, replay completed work, pause without compute charges during waits, and expose workflow primitives directly inside normal application code.
That does not make Step Functions obsolete. It makes the choice more precise.
The old question was, “Do I need orchestration?” The new question is, “Where should orchestration live?” If the workflow is part of application logic and the team wants to write it in Python, TypeScript, or Java, durable functions are attractive. If the workflow coordinates many AWS services, needs visual state inspection, uses native integrations, or belongs to a platform team rather than one application team, Step Functions is still the cleaner boundary.
This distinction matters because both services can now run long-lived processes. Lambda Durable Functions can execute for up to one year. Step Functions Standard workflows also have a one-year maximum execution time. Both can preserve progress. Both can retry. Both can wait. The difference is not duration. The difference is programming model, operational surface, integration depth, and how much workflow state you want outside your code.
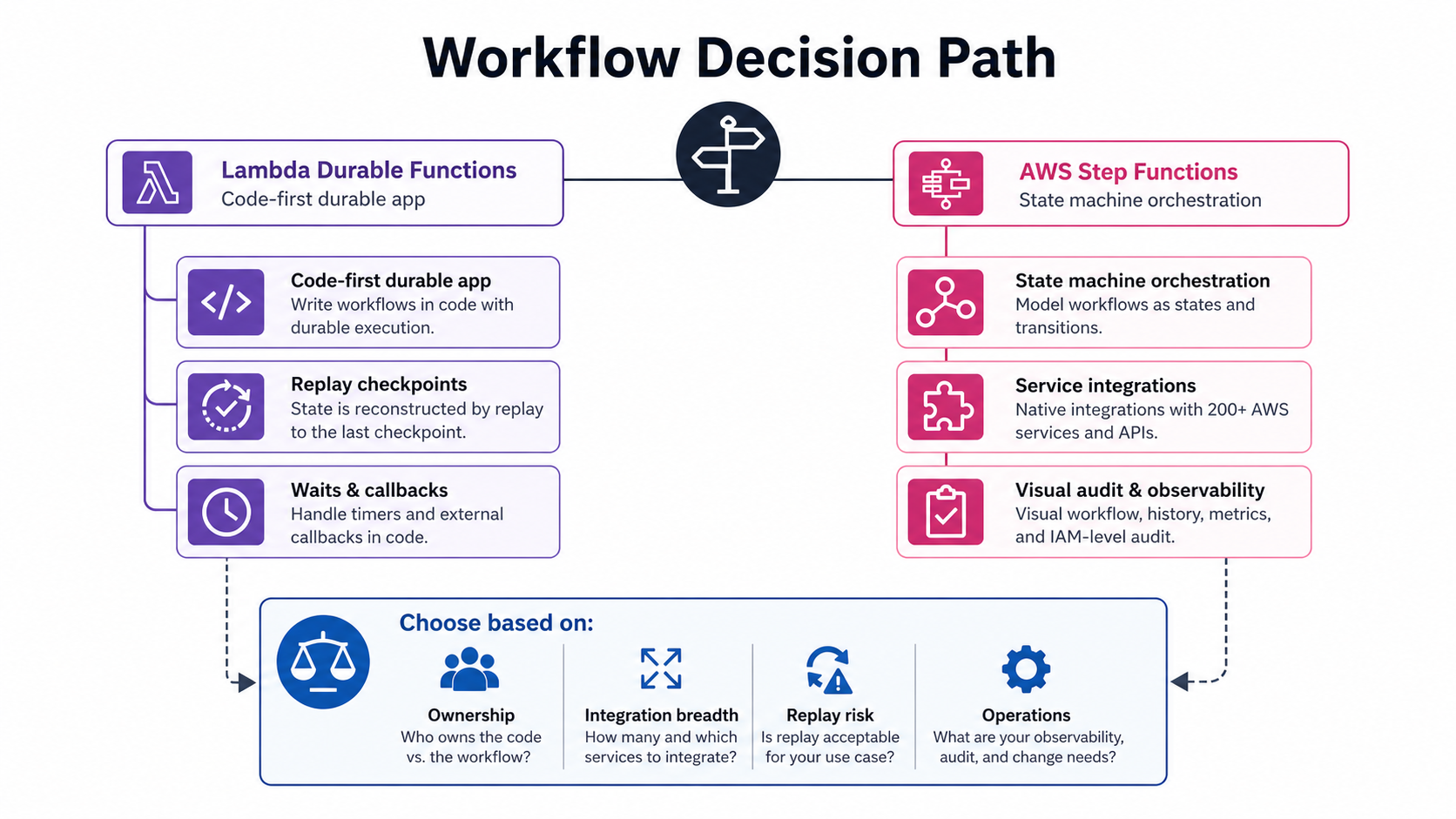
The Short Version
Use Lambda Durable Functions when the workflow is code-first, tightly coupled to one Lambda application, and easier to express as sequential logic with durable steps, waits, callbacks, maps, and parallel operations.
Use Step Functions when the workflow is architecture-first, crosses service boundaries, needs a visual state machine, uses many AWS service integrations, or must be owned and audited as a standalone orchestration layer.
| Requirement | Better default | Why |
|---|---|---|
| Business process is mostly one application | Lambda Durable Functions | The orchestration stays close to application code |
| Many AWS services are coordinated directly | Step Functions | Native integrations and visual state machines reduce glue code |
| Developers want Python/TypeScript/Java control flow | Lambda Durable Functions | SDK primitives fit normal programming constructs |
| Platform team owns the workflow | Step Functions | Clear standalone resource, IAM boundary, and execution history |
| Human approval waits inside app logic | Lambda Durable Functions | Callback and wait primitives are direct |
| Long cross-team process with audit needs | Step Functions | State history, graph, and operations model are easier to review |
| Huge fan-out data processing | Step Functions Distributed Map | Built for orchestration-level fan-out |
| Deterministic replay is hard to guarantee | Step Functions | State machine definition avoids replay hazards in arbitrary code |
If you remember one thing, remember this: durable functions are application durability; Step Functions are workflow orchestration.
What Lambda Durable Functions Actually Do
A durable function is still a Lambda function. The difference is that the handler is wrapped by a durable execution SDK. Instead of running once and forgetting everything after timeout or failure, the function creates checkpoints as it performs durable operations.
AWS describes the model as checkpoint and replay. When your function resumes after a wait, interruption, or retry, the code starts again from the beginning. Completed durable operations are not re-executed. The SDK returns stored results from the checkpoint log and continues from the next unfinished operation.
That sounds strange the first time you read it. It is also the core of the feature.
Consider a payment workflow:
@durable_execution
def handler(event: dict, context: DurableContext):
order = context.step(
lambda _: validate_order(event["orderId"]),
name="validate-order",
)
payment = context.step(
lambda _: authorize_payment(order),
name="authorize-payment",
)
context.wait(Duration.from_seconds(300))
context.step(
lambda _: capture_payment(payment["authorizationId"]),
name="capture-payment",
)
If the function pauses at the wait, Lambda does not keep compute running for five minutes. When it resumes, the handler starts from the top. The SDK sees that validate-order and authorize-payment already completed, returns their stored results, skips those calls, reaches the wait checkpoint, and then continues to capture-payment.
That model creates a new responsibility: deterministic code. During replay, the sequence of durable operations must match the checkpoint log. Random values, wall-clock calls, external API calls, and non-deterministic branching belong inside durable steps, not in the plain replay path.
The Primitives That Matter
The durable execution SDK gives you a small set of primitives. These are enough to build serious workflows, but each one has operational consequences.
| Primitive | What it does | Common use |
|---|---|---|
step |
Runs business logic with checkpointing and retry | Payment call, inventory update, validation |
wait |
Pauses without compute charges | SLA delay, polling interval, backoff |
createCallback |
Creates a callback ID and waits for external completion | Human approval, webhook response |
waitForCallback |
Combines callback creation and submission | External approval systems |
parallel |
Runs multiple durable branches concurrently | Independent service calls |
map |
Processes array items with durable tracking | Batch item processing |
| child context | Groups operations with isolated checkpoint logs | Sub-workflows and retry scopes |
invoke |
Invokes another Lambda and waits for result | Function composition |
waitForCondition |
Polls until a condition succeeds | External job status checks |
The strongest part is readability. A developer can express the workflow as normal code. That is useful when the orchestration is part of the business logic. A checkout flow, onboarding process, AI agent loop, or document approval chain often reads better as code than as a JSON state machine.
The tradeoff is that replay is now part of your programming model. With Step Functions, state transitions are explicit in the state machine. With durable functions, state transitions are implied by durable operation calls in your code. That gives developers more flexibility and more rope.
Limits You Need To Design Around
The numbers matter.
Lambda Durable Functions and Step Functions are both long-running, but their guardrails are different.
| Limit or quota | Lambda Durable Functions | Step Functions Standard | Why it matters |
|---|---|---|---|
| Maximum execution time | Up to 1 year | 1 year | Duration alone no longer decides the service |
| Running executions | 1,000,000 default for Lambda durable executions | 1,000,000 open executions per account per Region | Both can support large fleets, but quotas still need monitoring |
| Operation/history ceiling | 3,000 durable operations per durable execution | 25,000 events in one execution history | Long loops must be designed carefully |
| Persisted data | 100 MB durable execution storage written | 1 MB request size; execution history event limit applies | Payload discipline still matters |
| Direct checkpoint result | Results under 256 KB are checkpointed directly in certain contexts | State input/output quotas apply | Large payloads still need external storage |
| Timeout of one compute invocation | Lambda function timeout remains 15 minutes | State task timeout depends on state config | Durable waits do not mean one Lambda invocation runs forever |
| Definition model | Code plus SDK | Amazon States Language and service resource | Ownership and review differ |
The 3,000 durable-operation quota is the one I would highlight in design reviews. It is easy to accidentally build a workflow that polls every minute for days. That may look simple in code, but it becomes many durable operations. Use longer polling intervals, external events, callbacks, or Step Functions when the workflow is naturally a large state graph.
The 100 MB durable execution storage-written quota also matters. Do not treat durable functions as a database. Persist business records in DynamoDB, Aurora, S3, or the correct system of record. The checkpoint log is for workflow recovery, not analytics or archival.
Step Functions has its own sharp edges. The 25,000-event execution history limit can bite long loops in Standard workflows. Distributed Map, child executions, or splitting workflows can help, but you need to design for it. The service is visual and operationally mature, but it still has quotas.
Cost Model: Where The Bills Come From
Durable functions charge around Lambda execution and durable operations. Step Functions Standard charges per state transition, while Express charges per request and duration. That difference changes architecture.
For a workflow that waits 24 hours and does three pieces of work, durable functions can be very clean: run a step, checkpoint, wait without compute charges, resume later, run the next step. Step Functions Standard can also wait for long periods without paying for compute, but you pay for state transitions rather than the wait duration. Both can be economical.
For a workflow with hundreds of tiny state transitions, Step Functions Standard state-transition cost becomes visible. For a workflow with many small durable operations, durable-operation charges and checkpoint data writes become visible. There is no universal cheaper option.
The right cost review asks:
| Cost driver | Durable Functions question | Step Functions question |
|---|---|---|
| Steps | How many durable operations are created per execution? | How many state transitions happen, including retries? |
| Waiting | Are waits suspending compute properly? | Is Standard or Express the right workflow type? |
| Payloads | How much data is written into checkpoints? | How large is state input/output and execution history? |
| Retries | Are retries bounded and idempotent? | Do retries multiply transitions unexpectedly? |
| Fan-out | Are maps creating too many checkpoints? | Should Distributed Map or batching be used? |
| Logging | Are full payloads being logged? | Are execution histories and CloudWatch logs retained appropriately? |
If you need a simple rule: model cost per execution before choosing. A workflow diagram without an execution-count and retry-count estimate is not enough.
Replay Is Powerful, But It Is Not Free
Replay is the durable-functions superpower and the main source of bugs.
During replay, your handler runs again. That means any non-durable side effect outside a step can happen again unless you prevent it. Printing a log line twice is annoying. Charging a card twice is unacceptable.
Bad replay code looks like this:
@durable_execution
def handler(event, context):
charge_card(event["payment"]) # unsafe during replay
context.wait(Duration.from_minutes(5))
send_receipt(event["email"]) # unsafe during replay
Better code wraps side effects in durable steps:
@durable_execution
def handler(event, context):
payment = context.step(
lambda _: charge_card(event["payment"]),
name="charge-card",
)
context.wait(Duration.from_minutes(5))
context.step(
lambda _: send_receipt(event["email"], payment["id"]),
name="send-receipt",
)
Also avoid changing operation names casually. Names become part of the checkpoint story. If you rename charge-card to authorize-payment during a running execution, the replay path may no longer match what the execution history expects. Treat durable operation names like state names in Step Functions: stable, reviewed, and migrated carefully.
This is where Step Functions can be safer for some teams. A state machine definition makes state names and transitions explicit. It is harder to accidentally put a side effect “between states” because the definition is the workflow. With durable functions, the code is the workflow. That is more ergonomic for developers and more demanding for reviewers.
Where Step Functions Still Wins
Step Functions remains the better tool when orchestration is a platform concern.
First, it has native service integrations. AWS documentation describes Step Functions as orchestrating over 14,000 API actions from over 220 AWS services in the context of enhanced TestState local testing. That breadth matters. If your workflow calls Lambda, DynamoDB, ECS, EventBridge, Glue, Bedrock, SNS, SQS, and human approval tasks, a state machine may remove a lot of glue code.
Second, it has a visual execution model. Operations teams can open an execution and see where it is stuck. That is hard to beat during incidents. Developers can do similar observability for durable functions, but they have to build discipline around logs, metrics, execution IDs, and tracing.
Third, Step Functions is a clean resource boundary. A platform team can own the state machine, version it, attach IAM policies, test it, and expose it to application teams. Durable functions are owned with the Lambda function code. That may be perfect for one product team and wrong for a shared business process.
Fourth, Step Functions has mature testing improvements. The enhanced TestState API now supports local testing of workflow behavior, mocked integrations, Map and Parallel states, context object simulation, retry and catch testing, and CI/CD integration. That closes one of the old complaints: state machines were hard to test before deployment. They are much easier now.
If you are already using Step Functions well, do not migrate just because durable functions exist. Revisit workflows that are awkward as state machines but natural as code.
Where Durable Functions Win
Durable functions shine when the workflow is part of application code.
Think of an AI agent that needs to call a model, wait for a human review, call a tool, retry an external vendor, and then write a final answer. The logic may be easier to express in TypeScript than in Amazon States Language. You can use normal language features, normal unit testing, normal package management, and normal application abstractions.
They also fit teams that already think in Lambda. If you have a codebase with validators, domain services, adapters, and tests, durable functions let you keep that shape. Step Functions would force you to split orchestration out into a separate state machine, which may or may not be cleaner.
Durable waits are also valuable. Waiting without compute charges makes human-in-the-loop workflows practical without keeping a function warm. That is useful for approvals, external job polling, vendor callbacks, and long-running remediation.
Finally, durable functions can reduce the number of moving pieces. A small workflow that used to require a state machine plus several Lambda functions may become one durable Lambda. Fewer resources can mean faster development and simpler deployment. But do not confuse fewer resources with lower risk. The risk moves into code review.
A Production Design Pattern
For durable functions, I like a three-layer structure:
- Handler and durable orchestration.
- Domain services with idempotent operations.
- Adapters for AWS services and external APIs.
That split is not cosmetic. It keeps replay-aware code small. The handler should decide durable order, call named durable operations, and pass stable inputs. Domain services should own business rules and idempotency keys. Adapters should own boto3 clients, HTTP clients, retries, timeouts, and serialization. When those concerns mix, replay bugs get hard to spot in review.
For Step Functions, I use a similar split with different artifacts:
| Layer | Step Functions artifact | Review owner |
|---|---|---|
| Orchestration | ASL definition, state names, retries, catches, timeouts | Platform and application engineers |
| Business work | Lambda functions, ECS tasks, service integrations | Application team |
| Contracts | Event schemas, input/output examples, failure envelopes | API or platform team |
| Operations | CloudWatch alarms, dashboards, execution retention, DLQs | SRE or operations team |
That table is why some teams should prefer Step Functions even when durable functions look more ergonomic. If the workflow is a cross-team contract, the state machine gives reviewers something concrete to inspect. If the workflow is private application behavior, the code-first durable model may reduce ceremony.
For durable functions, add one more review rule: every external side effect must have an idempotency key visible in code. A reviewer should be able to point at the payment call, email send, ticket update, or database write and explain why replay cannot duplicate harm. For Step Functions, require the same evidence in state input, task parameters, and downstream Lambda code. Different orchestration models do not remove distributed-systems rules. They only move where those rules are expressed.
I would also tag long-lived executions with a business key. A one-year workflow without a searchable customer ID, order ID, incident ID, or approval ID becomes hard to operate. The execution ID is useful for machines. The business key is what an on-call engineer has when a user reports a problem.
The handler should be thin. It should call durable operations with stable names. Domain services should be deterministic where possible and idempotent where side effects exist. Adapters should handle retries, timeouts, and request IDs.
@durable_execution
def handler(event: dict, context: DurableContext):
order_id = event["orderId"]
order = context.step(
lambda _: order_service.validate(order_id),
name="validate-order",
)
approval = context.wait_for_callback(
lambda callback_id: approval_service.request(order, callback_id),
name="request-manager-approval",
config=WaitForCallbackConfig(timeout_seconds=86400),
)
if not approval["approved"]:
return {"status": "rejected", "orderId": order_id}
return context.step(
lambda _: fulfillment_service.submit(order),
name="submit-fulfillment",
)
In tests, verify replay behavior. Test that operation names stay stable. Test that external side effects happen inside steps. Test that callbacks time out. Test that duplicate invocations do not duplicate business actions.
If this feels like too much application discipline for your team, use Step Functions.
Observability and Operations
Step Functions gives you a native execution graph. Durable functions require more intentional telemetry.
At minimum, every durable execution should log:
- Durable execution ID
- Business correlation ID
- Current durable operation name
- Attempt number
- Replay indicator if available
- External request ID for every service call
- Callback ID for human or external waits
- Final status and reason
For CloudWatch, create alarms on durable execution failures, callback timeouts, checkpoint API errors, and unusual execution age. For Step Functions, alarm on failed executions, timed-out executions, throttling, and history-limit risk if your workflows loop heavily.
If you already use OpenTelemetry with CloudWatch, add durable execution IDs as span attributes. If you use AWS X-Ray for distributed tracing, make sure replay does not create misleading traces for already-completed steps. Trace design gets trickier when code can replay without redoing work.
For incident response, document how to answer these questions:
| Question | Durable Functions evidence | Step Functions evidence |
|---|---|---|
| Where is the workflow stuck? | Durable execution state, logs, current operation | Execution graph and event history |
| Did a side effect run twice? | Idempotency keys and adapter logs | Task state history and downstream logs |
| Why did it wait? | Wait or callback operation log | Wait state or task token state |
| Can it be stopped? | Durable execution stop API and app policy | StopExecution and state machine policy |
| Can it be replayed safely? | Determinism tests and operation naming | State machine version and execution input |
Migration: From Step Functions to Durable Functions
Do not migrate a working Step Functions workflow just to reduce resource count. Migrate when the state machine has become a poor fit.
Good candidates:
- The workflow is owned by one application team.
- Most states are Lambda tasks that call back into the same codebase.
- Business logic is hard to review because it is split across ASL and code.
- The team wants normal unit tests around orchestration logic.
- The execution has modest operation count and predictable payload size.
Bad candidates:
- The workflow coordinates many AWS services without Lambda glue.
- Operations teams rely on the visual execution graph.
- The state machine is shared across teams.
- Execution history and audit are more important than code ergonomics.
- The workflow uses large fan-out or complex service integrations.
Use a strangler migration. Wrap one Step Functions branch in a durable function. Keep the outer workflow intact. If that works well, move another branch. This avoids a risky all-at-once rewrite.
Migration: From Lambda Glue to Durable Functions
The better migration is often from fragile Lambda glue to durable functions.
If you have a Lambda that writes intermediate state to DynamoDB, schedules EventBridge callbacks, polls an external API, and manually deduplicates work, durable functions may remove custom orchestration code. You still need a system of record. But you may not need as much homemade retry and resume logic.
Look for these smells:
- A table named
workflow_statethat only exists to resume Lambda logic. - Manual “current_step” fields.
- EventBridge Scheduler jobs created for one-off waits.
- SQS messages that represent workflow progress instead of business events.
- Custom retry counters in DynamoDB.
- Support tickets about stuck intermediate states.
Durable functions were built for that pain.
How This Fits With Other AWS Serverless Patterns
Durable functions do not replace every serverless pattern. They sit next to them.
Use SQS plus Lambda event source mapping when you need queue-driven work distribution and backpressure. Use EventBridge plus Step Functions when you need event routing and standalone orchestration. Use Lambda S3 Files when the workflow needs a shared workspace or large file context. Use Lambda layers and custom runtimes when packaging and runtime control are the main problem.
The architecture should not be “durable functions everywhere.” It should be “durable functions where code-first durability reduces complexity.”
Final Decision Framework
Ask these questions in order:
- Is the workflow mostly one application or a cross-service business process?
- Would a developer understand it faster as code or as a visual state machine?
- How many operations or transitions will one execution create?
- Is replay determinism easy to guarantee?
- Does the workflow need native integrations to many AWS services?
- Who owns production support: the application team or platform team?
- What evidence will an auditor or incident commander need?
- What is the rollback path if the workflow definition changes?
If most answers point to one application team, code-first logic, modest operation counts, and durable waits, choose Lambda Durable Functions. If most answers point to cross-service orchestration, visual auditability, broad AWS integrations, and platform ownership, choose Step Functions.
The best AWS architectures usually do not pick one tool forever. They use the right boundary for the job. Durable functions make Lambda a stronger workflow runtime. Step Functions remains the orchestration backbone when the workflow needs to stand outside the application.
Sources
Explore more like this

Golden AMI Pipelines with EC2 Image Builder and AWS CDK L2 Constructs
An EC2 Image Builder component is immutable. Change one line and you need a new version. The recipe referencing that component is immutable too, and the pipeline references the recipe....

CloudFormation Pre-Deployment Validation: Safer CDK and Stack Operations
CloudFormation now runs pre-deployment validation automatically on every CreateStack and UpdateStack operation, not only while creating change sets. A malformed property or resource-name collision can fail before AWS provisions or...


Comments