OpenAI on Amazon Bedrock: Codex, GPT-5.5, and Managed Agents for AWS Teams

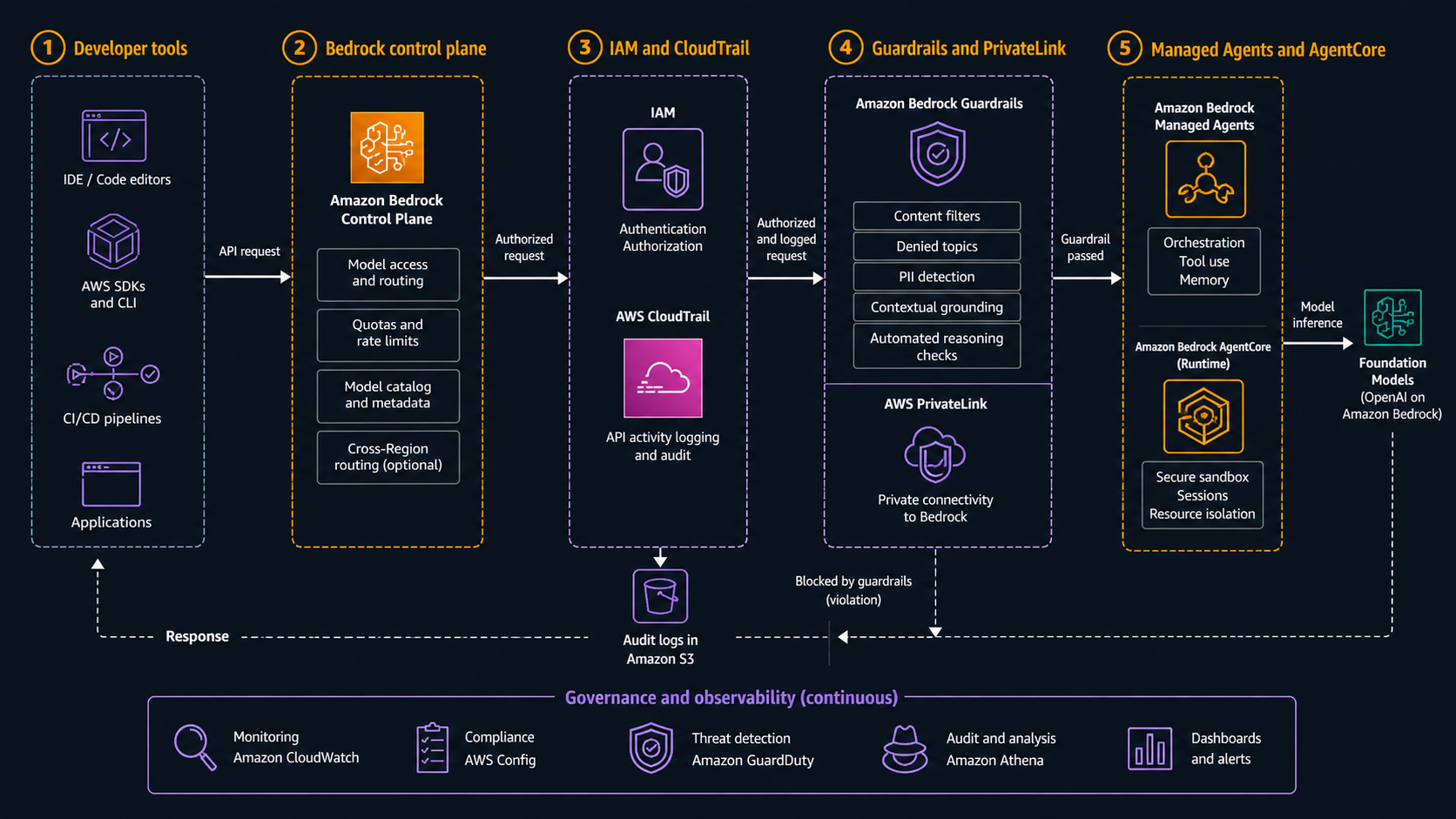
On April 28, 2026, AWS announced something that changes the enterprise AI architecture conversation: OpenAI models, Codex on Amazon Bedrock, and Amazon Bedrock Managed Agents powered by OpenAI are coming to Bedrock in limited preview. That is not just another model card in a console. It moves OpenAI workloads into the same AWS control plane where many teams already enforce IAM, CloudTrail, encryption, PrivateLink, guardrails, procurement controls, and deployment approvals.
That matters because most serious AI adoption does not fail at the prompt layer. It fails at the boring layer: identity, logging, network boundaries, data movement, cost allocation, audit evidence, and the question nobody wants to answer after a coding agent touches production infrastructure: who allowed this action, what did it read, what did it change, and where is the log?
AWS is positioning the launch around three pieces. The first is access to the latest OpenAI models through Bedrock. The second is Codex on Bedrock, where teams can use the OpenAI coding agent through AWS environments and tools. The third is Bedrock Managed Agents powered by OpenAI, with AgentCore as the default compute environment. The right way to read the announcement is not “OpenAI is now on AWS.” It is “OpenAI workloads can now be governed like AWS workloads.”
If you already use Bedrock for internal AI apps, this should simplify vendor sprawl. If you already use OpenAI for high-reasoning coding or agent tasks, this gives your AWS platform team a cleaner governance path. If you are responsible for regulated workloads, the announcement is interesting but not a free pass. Limited preview means you still need to verify model availability, data boundaries, pricing, support terms, and exact feature behavior before you move a sensitive workload.
For a currently available Anthropic model and a concrete production rollout, the Claude Opus 5 on Amazon Bedrock guide covers model access, zero data retention, canary testing, observability, and rollback.
What AWS Actually Announced
The headline has three parts, and each solves a different problem.
| Announcement | What it gives you | What to verify before production |
|---|---|---|
| OpenAI models on Amazon Bedrock | Access to OpenAI frontier models through Bedrock services and controls | Region support, model IDs, pricing, quota, logging detail, guardrail behavior |
| Codex on Amazon Bedrock | OpenAI coding agent inside AWS environments, with AWS authentication and Bedrock inference | Repository access boundaries, execution sandboxing, approval flow, audit evidence |
| Bedrock Managed Agents powered by OpenAI | Production-ready OpenAI-powered agents running in AWS, integrated with AgentCore | Agent identity, tool permissions, network path, memory retention, action logs |
The AWS What’s New post says the OpenAI models on Bedrock inherit controls customers already use with Bedrock, including IAM, AWS PrivateLink, guardrails, encryption, and CloudTrail logging. The same post says Codex on Bedrock will be available through the Codex CLI, desktop app, and Visual Studio Code extension, and that customers authenticate with AWS credentials while inference runs through Bedrock. It also says Managed Agents gives every agent its own identity, logs each action, runs in your environment, and uses Amazon Bedrock for inference.
Those details are the story. Bedrock is not only a model gateway. For platform teams, it becomes the policy boundary. A direct SaaS API key can be easy for a developer to start with, but it is usually painful for a security team to govern across dozens of teams. Bedrock gives you a familiar set of AWS primitives: IAM roles, CloudTrail event history, service control policies, VPC endpoints where supported, CloudWatch metrics, account-level budgets, and tagging patterns. It does not automatically make every workload safe, but it gives you tools that fit the AWS operating model.
There is also a second detail that matters to finance teams: AWS says usage of both OpenAI models and Codex can be applied toward existing AWS cloud commitments. That will not make bad usage cheap, and it does not replace model-level cost controls, but it changes procurement friction. Many companies already have AWS commitments. If OpenAI usage can land under that commercial umbrella, the internal approval path gets shorter.
Why This Is Bigger Than Model Access
Adding a model to Bedrock is useful. Adding a coding agent and a managed agent runtime is more important.
Model access mostly answers: “Can my application call this model?” Codex on Bedrock answers a harder question: “Can a coding agent operate inside my engineering environment without becoming a shadow admin?” Managed Agents answers: “Can I run an agent that takes actions without building my own identity, memory, logs, runtime, and governance layer from scratch?”
Those are different architecture problems.
A chat application can tolerate a simple request-response model call. A coding agent touches repositories, issue trackers, terminals, package managers, cloud templates, deployment scripts, and sometimes production diagnostics. A business agent may call CRM, ticketing, HR, procurement, finance, or observability tools. The risk is not only wrong text. The risk is wrong action.
That is why the identity claim in the announcement deserves attention. If every managed agent has its own identity and logs each action, you can start to separate agent behavior by purpose:
| Agent type | Identity pattern | Tool boundary | Audit question |
|---|---|---|---|
| Code review agent | Read-only repository role | Pull requests, static analysis, issue comments | What files did it inspect and what did it recommend? |
| Remediation agent | Scoped engineering role | Runbooks, CloudWatch, safe automation functions | What incident did it touch and what commands ran? |
| FinOps agent | Billing read role | Cost Explorer, CUR data, tagging reports | What spend data did it query and what recommendation did it produce? |
| Customer support agent | Customer-data role with redaction | CRM, ticketing, knowledge base | What customer record was accessed and why? |
| Platform agent | High-friction break-glass role | Deployment approvals, IaC checks, service catalog | Who approved the action and what guardrail was evaluated? |
This is the right mental model: do not create “the AI agent.” Create specific agents with specific identities and small permissions. The announcement gives you a reason to revisit your agent platform design before every team invents its own.
BitsLovers already covered the operational side of AWS agents in the Bedrock AgentCore feature guide and the safety side in the Bedrock trust and safety checklist. OpenAI on Bedrock sits between those two concerns. It adds model capability and coding-agent ergonomics, but the winning architecture is still about controls.
The New Bedrock Control Plane
The strongest argument for Bedrock is that it lets the cloud platform team reuse AWS controls instead of creating a second governance universe.
For OpenAI models, that means a request can flow through a familiar pattern:
- A workload assumes an IAM role.
- The role has permission to invoke a specific Bedrock model or agent path.
- Network access can be constrained through approved AWS paths where the service supports it.
- Invocation events and related activity are logged through AWS-native telemetry.
- Guardrails, encryption, and account-level policy can be applied around the workload.
- Cost can be allocated through AWS billing and existing commitment structures.
The exact implementation still depends on the model, region, API, and preview terms. But the architecture target is clear: keep AI access inside the same AWS governance frame you use for other production systems.
That does not mean you should let every application invoke every model. In mature environments, model access should look more like database access than internet access. Teams should request access to a specific model family for a specific use case, environment, and data class. Platform teams should maintain a registry that says which teams can use which models, which guardrails apply, whether customer data is permitted, whether outputs can trigger actions, and what logs must be retained.
Here is a practical baseline.
| Control | Minimum production rule | Why it matters |
|---|---|---|
| IAM | Separate roles per app, agent, and environment | Prevents one prompt path from becoming a universal AI credential |
| Network | Prefer private AWS paths where available | Reduces accidental public egress and simplifies traffic review |
| Logging | Retain invocation, tool-call, and agent-action logs | Makes incident review possible |
| Guardrails | Apply policy by data class and use case | A coding agent and a customer chat agent need different controls |
| Cost | Tag workloads and set budget alarms | Token usage can scale faster than normal request volume |
| Data | Classify prompts, retrieved context, tool outputs, and generated artifacts | Sensitive data often enters through context, not only user prompts |
| Deployment | Require approvals before agent actions mutate production | Reasoning quality is not a change-management process |
This is where cross-account Bedrock guardrails becomes relevant. If you centralize AI safety policy at the organization level, OpenAI on Bedrock becomes easier to operationalize across multiple AWS accounts. If every account configures guardrails differently, your audit story gets messy fast.
Codex on Bedrock Changes the Coding Agent Boundary
Codex on Bedrock is the piece DevOps teams will feel first.
The direct Codex experience is useful because it can inspect code, propose changes, run commands, and work inside developer tools. The Bedrock version matters because enterprise teams usually need a different boundary than a personal developer workflow. They need AWS authentication, AWS billing, and AWS logs around the agent path.
The announcement says Codex on Bedrock will be available through the Codex CLI, desktop app, and VS Code extension. That is important. Developers keep their existing surfaces, while platform teams get a better chance to enforce AWS-side access controls.
But the risk profile is not small. A coding agent can create excellent pull requests. It can also create expensive CI loops, leak secrets into logs, apply outdated Terraform, delete a security group rule, or produce a patch that passes unit tests and fails under load. The solution is not to ban coding agents. The solution is to put them on rails.
For a production engineering organization, I would separate Codex usage into four tiers.
| Tier | Allowed actions | Required controls | Good starting scope |
|---|---|---|---|
| Read-only analysis | Read code, summarize, explain, suggest | Repository read token, no shell, no secrets | Documentation, onboarding, code review |
| Patch authoring | Create branches and diffs | PR-only writes, branch protection, tests | Low-risk app code, docs, test generation |
| Controlled execution | Run tests, linters, build commands | Ephemeral sandbox, no production credentials | CI repair, dependency upgrades |
| Operational remediation | Query telemetry, run approved automation | Human approval, break-glass logging, scoped functions | Incident runbook steps only |
Do not start with tier four. Start with read-only and patch authoring. Build the trust path. Then add controlled execution. Operational remediation should be a separate program with serious approvals.
This connects directly with GitHub Copilot versus Kiro for DevOps. Coding agents are becoming less about autocomplete and more about delegated engineering work. The real differentiator is not whether the model can write Python. It is whether the workflow can prove where the change came from, what evidence the agent used, and who approved the final action.
Managed Agents Need Identity Before Tools
Most agent demos start with tools. That is backwards.
Start with identity. Then memory. Then tools. Then approvals.
The AWS announcement says each Bedrock Managed Agent powered by OpenAI has its own identity and logs each action. If that design lands cleanly in production, it gives teams a better starting point than a generic Lambda function with a broad IAM role and a pile of tool credentials.
Agent identity should be specific enough that CloudTrail and application logs tell a readable story. “agent-prod” is not specific enough. “claims-refund-agent-prod” or “eks-diagnostics-agent-readonly-prod” is closer. The identity should map to a data classification, an owner, an approval group, and a runbook.
For actions, the smallest useful pattern is a tool gateway. Do not give an agent raw access to every API it might need. Expose narrow operations:
tools:
- name: get_service_health
action: read
scope: cloudwatch:service-dashboard
environment: prod
- name: open_incident_summary
action: write
scope: jira:incident-project
approval: none
- name: restart_worker_service
action: mutate
scope: ecs:service/payments-worker
approval: human-required
The tool gateway should log input, output, decision metadata, and approval context. It should also enforce maximum payload size, timeout, retry behavior, and sensitive field redaction. You do not want the model deciding whether a request should include a full customer record. That policy belongs outside the model.
For memory, use the same discipline. Memory retention can improve continuity, but it also creates a new data store. Decide what can be remembered, for how long, and at what granularity. A support agent may remember ticket context. It should not remember raw payment card data. A coding agent may remember repository architecture. It should not remember secrets found during a scan.
What OpenAI Model Support Means for Application Code
There are two OpenAI-on-Bedrock tracks to keep separate.
The limited-preview announcement talks about the latest OpenAI frontier models, including GPT-5.5 and GPT-5.4 in the AWS News Blog roundup. The public Bedrock documentation for OpenAI models also describes OpenAI open-weight models such as gpt-oss-20b and gpt-oss-120b, both with a 128,000-token context window, text input, and text output. Those are not the same thing as every limited-preview frontier model. Keep your article, architecture, and code explicit about which model family you are using.
That distinction matters because application code often hardcodes assumptions:
| Assumption | Why it can break | Safer pattern |
|---|---|---|
| One OpenAI API shape works everywhere | Bedrock Converse, InvokeModel, and OpenAI-compatible endpoints have mapping details | Create a model adapter layer |
| Every model supports the same tools | Tool use, streaming, guardrails, and batch behavior vary | Maintain capability metadata per model |
| Context window equals useful context | 128K tokens can still produce expensive, noisy prompts | Use retrieval, summarization, and prompt budgets |
| Reasoning output is always safe to log | Some responses may include reasoning or sensitive context | Redact and classify logs |
| Preview behavior is stable | Limited preview features can change | Isolate preview workloads behind feature flags |
For application teams, the adapter layer is worth the extra code. Your business logic should call generate_remediation_plan() or classify_ticket() rather than directly embedding model IDs and request details across the codebase. Put Bedrock request construction, guardrail headers, retry policy, logging, and token budgeting in one library.
Here is a simple Python shape for that boundary:
import boto3
import json
class BedrockOpenAIClient:
def __init__(self, model_id: str, region_name: str = "us-west-2"):
self.model_id = model_id
self.client = boto3.client("bedrock-runtime", region_name=region_name)
def complete(self, system: str, user: str, max_tokens: int = 800) -> str:
body = {
"model": self.model_id,
"messages": [
{"role": "system", "content": system},
{"role": "user", "content": user},
],
"max_completion_tokens": max_tokens,
"temperature": 0.2,
"stream": False,
}
response = self.client.invoke_model(
modelId=self.model_id,
body=json.dumps(body),
)
payload = json.loads(response["body"].read().decode("utf-8"))
return payload["choices"][0]["message"]["content"]
In real production code, add request IDs, model capability checks, structured logging, prompt redaction, guardrail identifiers, retry policy, and circuit breakers. The point is the boundary. Do not scatter model calls through application code.
The Security Model I Would Require
OpenAI on Bedrock should not bypass your existing AI safety program. It should strengthen it.
At minimum, define four classifications: public, internal, confidential, and restricted. Then decide which model, tool, memory, and logging rules apply to each. Public prompts can use broader experimentation. Confidential prompts should require stricter guardrails, retention controls, and access logging. Restricted prompts may need to be blocked unless a specific approved use case exists.
For coding agents, add repository classes. A documentation repo is different from an infrastructure repo. A Terraform module repo is different from a production secrets rotation repo. Codex should not get the same permissions everywhere.
For Managed Agents, split tool permissions by action:
| Tool action | Example | Default approval |
|---|---|---|
| Read | Get CloudWatch alarm history | No approval, log everything |
| Draft | Create incident summary or pull request | No approval, require human review before merge |
| Recommend | Suggest scaling change | No approval, record evidence |
| Mutate low risk | Update ticket status | Policy-based approval |
| Mutate high risk | Change IAM, deploy, delete, restart production | Human approval required |
The dangerous pattern is allowing an agent to observe a problem, decide on a fix, and execute it through a broad role without a human or policy gate. That is not autonomy. That is unbounded automation with a language model in the middle.
If you already use AWS Security Hub risk correlation or AWS Organizations and Control Tower governance, agent permissions should become part of that same review process. Agents are principals. Treat them like principals.
Cost and Commitment Implications
AWS saying OpenAI and Codex usage can apply toward existing AWS cloud commitments is a procurement feature, not a cost-control strategy.
You still need budgets. You still need per-application attribution. You still need prompt and output limits. You still need to review whether a task belongs on a frontier model, an open-weight model, a smaller model, a rules engine, or plain code.
Use a tiered model policy:
| Workload | Recommended model class | Cost control |
|---|---|---|
| Simple classification | Small or open-weight model | Low max tokens, batch where possible |
| Codebase reasoning | Codex or high-reasoning model | Repository scope limits, job budget |
| Customer support drafting | Strong text model with guardrails | Per-ticket token cap |
| Agentic remediation | High-reasoning model plus tool gateway | Approval gates and per-action budget |
| Offline analysis | Batch inference if supported | Scheduled budget and input size cap |
The trap is using the best available model for every request. Model routing matters. The fact that a model has a 128K context window does not mean you should paste 128K tokens into every call. Token budgets are architecture.
This is where Bedrock granular cost attribution becomes important. If you cannot answer “which team spent this money and on which use case,” you are not ready to scale model access. Spend without attribution becomes a political fight, not an engineering problem.
Migration Plan for Existing OpenAI Workloads
Do not migrate everything at once. Start with workloads that benefit from AWS governance but do not carry the highest blast radius.
Phase one is inventory. List every OpenAI API key, application, owner, environment, model, data class, and monthly spend. You will probably find more usage than expected. Include local developer tools, CI jobs, test scripts, support tooling, and proof-of-concept agents.
Phase two is classification. Decide which workloads are good candidates for Bedrock. Good candidates include internal engineering assistants, code review helpers, customer-support drafting with guardrails, agent prototypes that need AWS telemetry, and AI apps already running in AWS. Bad first candidates include workloads that depend on unsupported model features, strict latency assumptions, or preview-only behavior that cannot change.
Phase three is adapter implementation. Create one internal Bedrock model client. Add structured logs, request IDs, guardrail configuration, prompt redaction, retry behavior, and token budgets. Build it once. Make teams use it.
Phase four is shadow testing. Run the Bedrock path side by side with the existing path for a small set of requests. Compare latency, output quality, moderation behavior, costs, logs, and failure modes. Keep human review in the loop.
Phase five is controlled cutover. Move one low-risk workload to Bedrock. Watch it for a week. Then expand.
Here is the migration checklist I would use.
| Step | Evidence required |
|---|---|
| Model access approved | Bedrock model access request, region, model ID |
| IAM role created | Least-privilege policy and owner |
| Network path reviewed | Public/private path documented |
| Logging enabled | CloudTrail, application logs, request IDs |
| Guardrails configured | Policy mapped to data classification |
| Cost attribution ready | Tags, budget, account mapping |
| Output review defined | Human review or automated checks |
| Rollback path tested | Existing provider or fallback behavior |
Do not skip rollback. Limited preview means you need a fallback if a model, region, quota, or API behavior changes.
What Not To Move Yet
Some workloads should wait.
Do not move regulated production decisions until you have written evidence for data handling, retention, model terms, and audit logs. Do not move fully autonomous production remediation until your approval and rollback process is boring. Do not move a coding agent into infrastructure repositories until branch protection, CI policy, secret scanning, and Terraform plan review are enforced.
Also be careful with workloads that require exact API compatibility. The Bedrock OpenAI documentation shows OpenAI-compatible chat completion usage for open-weight models, but it also documents Bedrock-specific mapping to Converse and InvokeModel. Build for adapters, not assumptions.
For agent workloads, avoid broad tool access. A managed agent that can call ten business systems is not automatically safer than a custom agent. It depends on identity, logs, data boundaries, and policy enforcement. The managed runtime helps, but it does not replace architecture.
The Practical Decision
Use OpenAI on Bedrock when the AWS control plane is the thing you were missing.
That means enterprise teams with existing AWS commitments, security teams that need CloudTrail and IAM alignment, platform teams standardizing model access, and DevOps teams that want Codex but need a governed path. It is also a strong fit for agent platforms that already use AgentCore or Bedrock guardrails.
Stick with direct provider APIs, at least for now, when you need a feature not exposed through Bedrock, a region not supported by the preview, a latency path you have already validated, or a product surface that depends on provider-native behavior. There is no shame in a hybrid model. The mistake is letting every team choose its own path without an inventory.
The best near-term move is simple: build an internal OpenAI-on-Bedrock reference architecture. Include IAM, model access, guardrails, logging, cost tags, a coding-agent policy, and a managed-agent tool gateway. Then pilot it with one real workload. Not a toy. Not production incident remediation. Something in the middle, like code review assistance or an internal support agent.
OpenAI on Bedrock is not the end of AI governance. It is a better place to start.
Sources
Explore more like this

Golden AMI Pipelines with EC2 Image Builder and AWS CDK L2 Constructs
An EC2 Image Builder component is immutable. Change one line and you need a new version. The recipe referencing that component is immutable too, and the pipeline references the recipe....

CloudFormation Pre-Deployment Validation: Safer CDK and Stack Operations
CloudFormation now runs pre-deployment validation automatically on every CreateStack and UpdateStack operation, not only while creating change sets. A malformed property or resource-name collision can fail before AWS provisions or...


Comments