Serverless Payloads Are Now 1 MB: Lambda, SQS, and EventBridge Architecture Changes

On January 29, 2026, AWS raised one of the quiet limits that shaped serverless architecture for years: asynchronous Lambda invocations, Amazon SQS messages, and Amazon EventBridge events can now carry payloads up to 1 MB. The old ceiling was 256 KB. That sounds like a simple quota change. It is not.
That extra 768 KB changes how you design event contracts, AI context envelopes, telemetry messages, and service-to-service workflows. It also creates a new class of mistakes. A 900 KB event can be perfectly valid and still be the wrong architecture if every consumer logs it, parses it, retries it, and sends it through three downstream systems.
AWS says the larger limit applies to asynchronous Lambda function invocations, Lambda triggered through SQS event-source mappings, Amazon SQS queues, and EventBridge event buses. Existing functions, queues, and buses get the enhancement automatically. If your application code still rejects messages at 256 KB, that behavior is now your limit, not the platform’s.
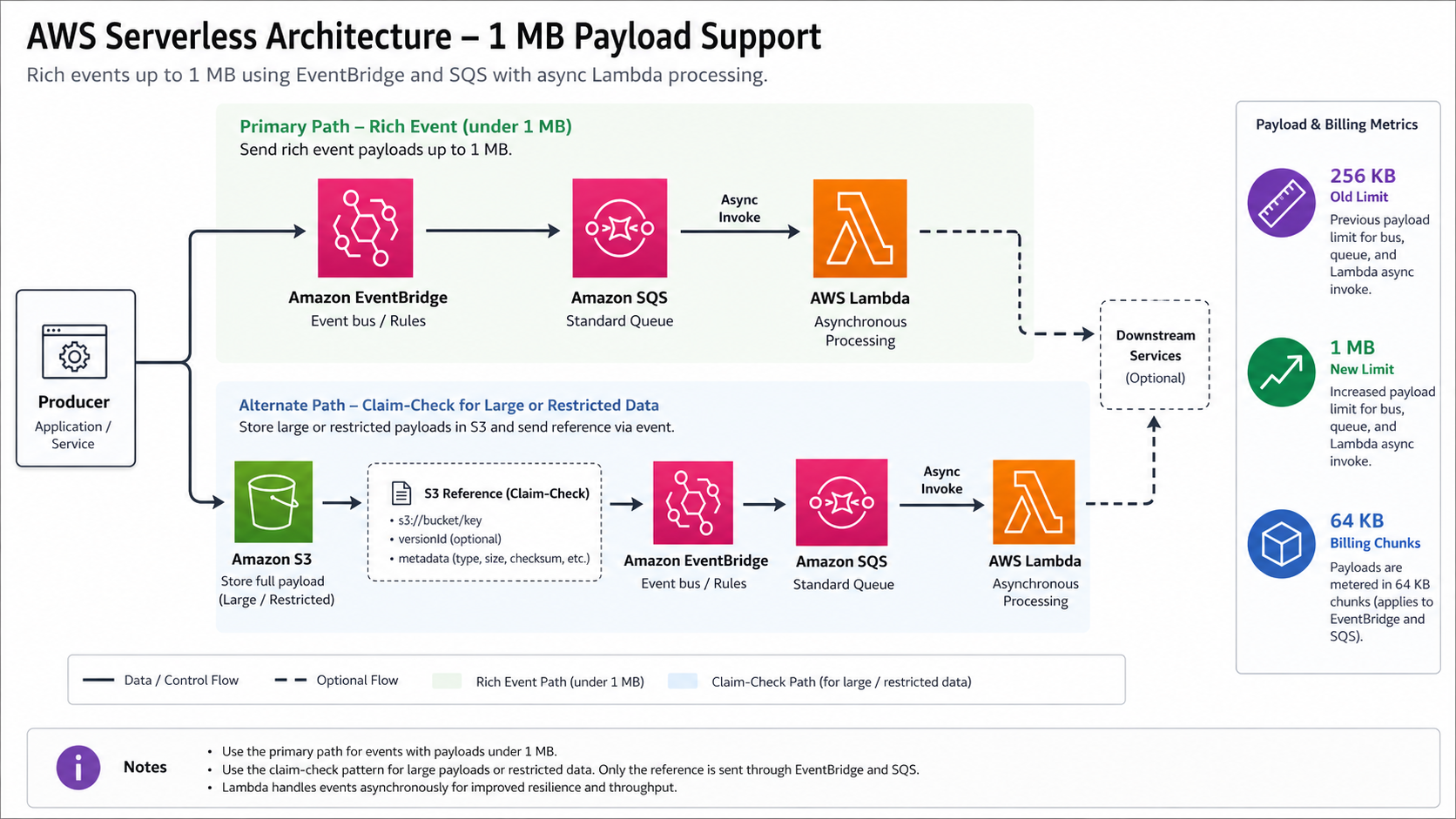
The right takeaway is not “put more data in every event.” The right takeaway is “the claim-check pattern is no longer mandatory for many normal rich events, but it is still the correct pattern for large, shared, governed, or reusable payloads.” This article is the migration guide I would use before letting a team raise payload budgets in production.
What Changed
The AWS Compute Blog announcement is specific. AWS increased the maximum payload size from 256 KB to 1 MB for three serverless paths: asynchronous Lambda invocations, Amazon SQS, and EventBridge. The blog also says the limit applies when Lambda is triggered by SQS event-source mapping, the AWS CLI, SDKs, the Lambda Invoke API, or services such as EventBridge.
That matters because the old 256 KB limit created awkward workarounds. Teams split events into chunks, compressed JSON, wrote large objects to S3, passed object keys through queues, and then wrote compensating logic for missing objects, stale keys, encryption policy, lifecycle cleanup, and partial failure. Some of those patterns were good. Some were forced by the limit.
The new platform baseline looks like this.
| Service path | Current payload limit | Old common workaround | What changes now |
|---|---|---|---|
| Lambda asynchronous invocation | Up to 1 MB | Store detail in S3 and pass a pointer | Many rich commands can be passed directly |
| Lambda through SQS event-source mapping | Up to 1 MB per SQS message | Chunk messages or use SQS Extended Client | Most structured job descriptions fit in one message |
| Amazon SQS | 1,048,576 bytes, or 1 MiB | Extended Client with S3 references | Direct messages can carry larger context |
| EventBridge PutEvents | Request total must be under 1 MB | Store event detail externally | A single custom event can carry nearly the full request if it is alone |
| EventBridge batch | Up to 10 entries per PutEvents request, total under 1 MB | Split batches aggressively | Batch size now depends on aggregate bytes, not only count |
The last row is easy to miss. EventBridge PutEvents can batch up to 10 entries, but the total request size must be less than 1 MB. One event can use almost the entire budget when it is the only entry. Ten events cannot each be 1 MB in one request.
That one detail should change client libraries. Your publisher should batch by bytes, not just by event count.
Why This Limit Mattered So Much
Serverless systems usually move state through messages. The smaller the message budget, the more often the architecture has to split “what happened” from “the context required to react to it.”
That split is not always bad. It is the foundation of the claim-check pattern: store the large payload in S3, DynamoDB, or another durable store, then send a compact reference through SQS or EventBridge. BitsLovers used the same idea in the Lambda and S3 shared workspace pattern, where S3 becomes the durable coordination layer for files that are too large or too long-lived for an invocation payload.
But forced claim checks carry operational cost. A downstream consumer must fetch the object, handle missing objects, verify encryption, parse object metadata, retry object reads, and decide who owns cleanup. That is reasonable when the payload is a report, image, PDF, model input, audit artifact, or reusable dataset. It is heavy for a 430 KB event that contains a customer profile snapshot and a few recent interactions.
The 1 MB limit changes the default for these cases:
| Workload | 256 KB architecture | 1 MB architecture | Keep claim check? |
|---|---|---|---|
| AI support context | S3 pointer for prompt context | Direct event with redacted conversation summary | Only for raw transcripts or attachments |
| Order fulfillment | Split order, customer, and shipping detail | Single event envelope with compact nested JSON | Only for documents, invoices, or images |
| Security finding | Send finding ID and fetch enrichment | Direct enriched finding for triage | Yes for raw evidence or packet captures |
| Telemetry batch | Compress or chunk aggressively | Batch related small signals into one message | Usually no, unless retention matters |
| ML inference request | S3 object key for all input | Direct compact feature payload | Yes for large tensors, media, or reused features |
This is why the change is more than convenience. It lets event-driven systems carry enough context for autonomous consumers to make better decisions. That is useful for AI agents, rule engines, analytics pipelines, and remediation workflows.
It also tempts teams to create oversized domain events that are harder to version and inspect.
The New Decision Rule
Before 2026, many teams used a simple rule: if it is larger than 256 KB, put it in S3 and pass a pointer. That rule is obsolete. Replace it with a four-question review.
| Question | If yes | If no |
|---|---|---|
| Is the payload under 1 MB after realistic metadata and UTF-8 encoding? | It can fit in Lambda, SQS, or EventBridge | Use S3 or another store |
| Does every consumer need most of the data immediately? | Direct payload is reasonable | Pass a smaller event and let interested consumers fetch detail |
| Is the payload sensitive, regulated, reusable, or long-lived? | Favor claim check with controlled access | Direct payload may be simpler |
| Will the payload be logged, archived, replayed, or copied across accounts? | Treat size as a cost and security multiplier | Size risk is lower |
My default recommendation is direct payloads for bounded, short-lived, redacted context that one or two consumers need immediately. Use claim checks for durable artifacts, raw data, customer-sensitive records, binary objects, evidence packages, or anything multiple systems will reuse.
The trap is thinking about only the producer. A producer sends one 900 KB event and moves on. A platform may store it in logs, archives, DLQs, traces, retries, replay systems, and downstream queues. One large message can become several large copies.
A Concrete Event Envelope
The 1 MB limit does not remove the need for event discipline. It makes event discipline more important.
For EventBridge, I would keep the event detail structured and versioned:
{
"source": "com.bitslovers.orders",
"detail-type": "OrderReadyForRecoveryReview",
"detail": {
"schemaVersion": "2026-05-01",
"eventId": "evt-01HX7E4B7K97A",
"correlationId": "order-87421",
"createdAt": "2026-05-01T15:20:00Z",
"classification": "internal",
"payloadBudgetBytes": 786432,
"customer": {
"id": "cust-9921",
"loyaltyTier": "gold",
"region": "us"
},
"summary": {
"latestIssue": "late delivery",
"previousComplaints": 2,
"lastOrderValueUsd": 148.21
},
"agentContext": {
"maxTokens": 4000,
"redactionPolicy": "support-v3",
"conversationSummary": "Customer reported..."
}
}
}
Notice what is missing. No raw payment details. No full transcript by default. No attachment bytes. No unbounded arrays. The event is richer than a pointer but still curated.
For SQS, the same discipline applies. If you send a 1 MB message to a queue with a Lambda event-source mapping, every batch can now carry much more data into one invocation. That can improve throughput by reducing lookups, but it can also increase memory pressure. The AWS announcement explicitly reminds teams that the Lambda 15-minute timeout and memory limits remain unchanged.
If your consumer parses large nested JSON, benchmark with realistic payloads. Do not guess.
Batching By Bytes, Not Count
Many publishers batch by entry count because EventBridge and SQS APIs have count limits. With 1 MB payloads, byte-aware batching becomes mandatory.
For EventBridge, a PutEvents request can include up to 10 entries, but the total request size must be under 1 MB. For SQS, a single request can include 1 to 10 messages with a maximum total payload of 1 MiB, and SQS pricing bills each 64 KB chunk as one request. EventBridge pricing also treats each 64 KB chunk of a payload as one event for event buses.
That means a single 1 MiB SQS payload is billed as 16 request chunks. A 256 KB EventBridge event is billed as 4 events. Larger messages are valid, but they are not free just because they are one API call.
Here is the rough publisher behavior I want.
import json
MAX_REQUEST_BYTES = 950 * 1024
MAX_ENTRIES = 10
def encoded_size(entry: dict) -> int:
return len(json.dumps(entry, separators=(",", ":")).encode("utf-8"))
def eventbridge_batches(entries):
batch = []
batch_bytes = 0
for entry in entries:
size = encoded_size(entry)
if size > MAX_REQUEST_BYTES:
raise ValueError(f"event too large for direct publish: {size} bytes")
if len(batch) == MAX_ENTRIES or batch_bytes + size > MAX_REQUEST_BYTES:
yield batch
batch = []
batch_bytes = 0
batch.append(entry)
batch_bytes += size
if batch:
yield batch
Use a margin below the hard limit. The EventBridge docs explain that the final event is larger than the entry size because EventBridge adds the JSON representation around it. A 1 MB business payload can become too large once metadata is included.
This is not overengineering. It is the difference between a high-throughput event publisher and a system that starts throwing size failures only under real production payloads.
Cost Changes With Payload Size
The most misleading sentence in a design review is “it is still only one message.”
For billing, one visible message can contain many billable chunks. AWS SQS pricing says every 64 KB chunk of a payload is billed as one request; an API action with a 1 MiB payload is billed as 16 requests. EventBridge pricing says each 64 KB chunk of an event bus payload is billed as one event. CloudWatch Logs charges by ingested and stored data volume, so full-payload logging can become the bigger bill.
Here is a simple way to reason about it.
| Payload size | 64 KB billing chunks | Relative logging pressure | Architecture note |
|---|---|---|---|
| 16 KB | 1 | Low | Normal event payload |
| 64 KB | 1 | Low to moderate | Still comfortable |
| 256 KB | 4 | Noticeable | Old hard-limit territory |
| 512 KB | 8 | High | Batch carefully, truncate logs |
| 1 MiB | 16 | Very high | Use only when the consumer needs it |
The number is not a bill by itself. You still need service-specific price, region, free tier, delivery path, and retry rate. But the multiplier is real. If a retry loop sends a 1 MiB message five times, you did not retry “one message” five times. You retried 80 billable 64 KB chunks in the SQS mental model.
The same cost logic applies to observability. In the OpenTelemetry and CloudWatch observability guide, the core idea is to emit telemetry that helps you debug without turning logs into a second data lake by accident. With 1 MB events, this becomes urgent. Log event IDs, schema versions, sizes, routing decisions, and redacted summaries. Do not log full payloads unless the use case and retention policy justify it.
Reliability Gotchas
Larger messages change failure modes. They do not remove them.
First, dead-letter queues become more valuable and more expensive. The AWS blog recommends DLQs for failed messages because larger payloads make full context useful during troubleshooting. That is true. But a DLQ full of 800 KB messages is also a storage and privacy liability. Set retention intentionally. Encrypt it. Restrict read access. Create a playbook for redaction before sharing examples in tickets.
Second, consumers need size-aware retry policies. A small malformed event and a huge malformed event can produce the same exception. The huge one costs more to retry and inspect. If validation fails because the schema is wrong, send it to a failure path quickly. Do not burn retry attempts on deterministic errors.
Third, visibility timeouts still matter. SQS message visibility timeout can be set from 0 seconds to 12 hours, and the default is 30 seconds. Larger payloads may take longer to parse, validate, and process, especially if the Lambda function calls an LLM or performs enrichment. Tune visibility timeout against realistic p95 and p99 processing time, not local tests with a tiny fixture.
Fourth, Lambda memory sizing changes. Parsing a 900 KB JSON payload usually uses more memory than 900 KB. Object overhead, transformations, validation libraries, and logging buffers add up. Watch memory usage and duration as payloads grow. A function that was cheap at 128 MB may need more memory to keep latency reasonable.
Finally, contracts get harder to evolve. A large event often contains more fields and nested structures. That increases the chance that a consumer starts depending on accidental detail. Use schema versions, deprecation windows, and consumer contract tests.
Security And Data Governance
The larger limit is attractive for AI workloads because richer context improves response quality. It is also a data governance risk.
The most common mistake is bundling raw customer context into a message because “now it fits.” Fit is not permission. A direct payload travels through every system on the path: event bus, queue, Lambda environment, logs, error handlers, DLQs, archives, replay tools, and sometimes cross-account targets.
Use a classification field in every rich event:
| Classification | Allowed direct payload | Required controls |
|---|---|---|
| Public | Documentation metadata, non-sensitive product facts | Normal logs allowed |
| Internal | Operational context, non-customer service state | Redacted logs and normal retention |
| Confidential | Customer summaries, support context, internal financial fields | Encryption, strict IAM, truncated logs, DLQ review |
| Restricted | Payment data, secrets, raw identity documents, regulated records | Prefer claim check or block direct event payload |
For confidential and restricted payloads, pass summaries rather than raw records. If the raw data must be available, use the claim-check pattern with S3, narrow IAM, object-level encryption, access logging, lifecycle policies, and a retention owner.
This is where the AWS cost anomaly detection playbook and security operations overlap. Payload size can be a cost anomaly, but it can also be a privacy anomaly. Emit metrics for payload bytes by source, event type, account, and environment. Alert on sudden growth.
Schema Governance For Rich Events
The larger payload limit makes schema governance more important, not less. A 30 KB event with five fields can be reviewed by inspection. A 700 KB event with nested arrays, optional enrichment blocks, and model-facing context needs formal contracts.
Use explicit schema versions. Avoid silent field reuse. Add a compatibility policy for every rich event type:
| Change | Compatibility | Deployment rule |
|---|---|---|
| Add optional field | Usually backward compatible | Producer can deploy first |
| Add required field | Breaking for old consumers | Deploy consumers first or create new version |
| Rename field | Breaking | Add new field, deprecate old field later |
| Change field meaning | Breaking even if name stays same | Create new schema version |
| Increase max array length | Potentially breaking | Load-test consumers and update payload budget |
| Move raw data into direct payload | Security-sensitive | Require data classification review |
If you use EventBridge Schema Registry, register the event types that matter and generate client bindings where useful. If you use OpenAPI, JSON Schema, protobuf, or another contract system, keep payload size constraints in the schema. A field that can grow without bound is a production incident waiting for traffic.
For teams building AI workflows, create a separate agentContext contract. That context should include redaction policy, token budget, prompt version, retrieval window, and source identifiers. It should not become a bag of arbitrary text. When the model output is wrong, operators need to know whether the failure came from missing context, stale context, an unsafe tool path, or bad model behavior.
Observability Queries Worth Adding
After the migration, add a small dashboard. The point is not beauty. The point is catching payload drift before it becomes a cost, latency, or privacy incident.
Track:
- Payload bytes by event type, producer, and environment.
- p50, p95, p99, and maximum payload size.
- Count of messages above 256 KB, 512 KB, and 900 KB.
- Lambda duration and memory usage grouped by payload-size bucket.
- SQS age of oldest message grouped by queue and approximate message size bucket.
- EventBridge failed entry count and payload-too-large validation failures.
- DLQ message count and average message size.
If you emit Embedded Metric Format from Lambda, keep the raw payload out of the log event and emit only the size and identifiers:
{
"_aws": {
"Timestamp": 1777651200000,
"CloudWatchMetrics": [
{
"Namespace": "ServerlessPayloads",
"Dimensions": [["Service", "EventType"]],
"Metrics": [{"Name": "PayloadBytes", "Unit": "Bytes"}]
}
]
},
"Service": "orders",
"EventType": "OrderReadyForRecoveryReview",
"PayloadBytes": 428123,
"SchemaVersion": "2026-05-01"
}
One alert I like is simple: page only when payload growth correlates with failures, but create a ticket when p95 crosses a design threshold. That keeps teams from ignoring steady bloat while avoiding noisy pages for one large but valid event.
Migration Plan
Do not flip every producer from 256 KB to 1 MB in one sprint. Treat this like an API contract migration.
- Inventory current workarounds. Find chunking code, S3 pointer schemas, compression flags, maximum message size settings, and validation rules that hardcode 256 KB.
- Measure real payloads. Capture p50, p95, p99, and maximum encoded byte size by event type. Do this before changing contracts.
- Classify event types. Decide which events should use direct payloads and which should keep claim checks.
- Update client libraries. Batch by bytes, not only by count. Add a safety margin below 1 MB.
- Add size metrics. Emit
payload_bytes,payload_classification,schema_version, andproducer_service. - Harden logging. Replace full payload logs with IDs, hashes, summaries, and selected fields.
- Test downstream memory. Benchmark Lambda functions with realistic 512 KB and 1 MB messages.
- Update DLQ runbooks. Include redaction, retention, replay, and access-review steps.
- Roll out by event type. Start with low-risk internal events. Watch cost, retries, and parsing errors.
- Remove obsolete complexity only after stability. Do not delete claim-check code paths until you know which consumers still need them.
For SQS-backed Lambda systems, review the SQS Lambda event-source mapping guide before increasing payload size. Batch size, visibility timeout, partial batch failure, and reserved concurrency all interact with message size.
For EventBridge systems, review the EventBridge and Step Functions patterns guide before pushing large decision context through the bus. EventBridge is a routing fabric. It should not become a hidden document store.
A Practical Architecture Pattern
The pattern I like is a dual payload strategy.
Direct payloads carry a curated, bounded context envelope. Claim checks carry raw, large, reusable, or regulated data. Every event tells the consumer which strategy it uses.
{
"schemaVersion": "2026-05-01",
"payloadMode": "direct",
"payloadBytes": 428123,
"dataClass": "confidential",
"summary": {
"caseId": "case-881",
"issueType": "delivery-delay",
"riskScore": 0.73
},
"context": {
"recentInteractions": [
{"channel": "chat", "daysAgo": 1, "summary": "Asked for refund status"}
]
},
"largeObjects": []
}
When the same workflow needs raw evidence, switch modes:
{
"schemaVersion": "2026-05-01",
"payloadMode": "claim-check",
"payloadBytes": 18321,
"dataClass": "restricted",
"summary": {
"caseId": "case-881",
"issueType": "delivery-delay"
},
"largeObjects": [
{
"type": "raw-transcript",
"bucket": "company-sensitive-workflow-data",
"key": "cases/case-881/transcript.json",
"sha256": "..."
}
]
}
This keeps the common path simple without throwing away the safer path. It also makes reviews easier. A pull request can change an event from direct to claim-check, and reviewers immediately know that access, retention, and cleanup must be checked.
When To Use The Full 1 MB
Use the full limit rarely. It is a ceiling, not a target.
Good reasons to approach 1 MB:
- An AI agent needs a redacted context package to make a one-time decision.
- A downstream consumer must process a complete but compact domain snapshot immediately.
- A security workflow needs enriched finding detail for triage and the evidence is already summarized.
- A short-lived batch of related events is more reliable as one atomic message than as many tiny messages.
Bad reasons:
- The producer has no schema discipline.
- The team wants to avoid designing a proper storage model.
- Logs are used as the primary debugging interface.
- Multiple consumers need different slices of the data.
- The payload contains raw confidential data because redaction was inconvenient.
If a senior engineer asks, “Why is this event 900 KB?” the answer should be specific. “Because it fits” is not a design answer.
Sources
- AWS Compute Blog: More room to build: serverless services now support payloads up to 1 MB
- AWS SQS Developer Guide: Amazon SQS message quotas
- AWS EventBridge User Guide: Sending events with PutEvents
- AWS SQS Pricing: Amazon SQS pricing
- AWS EventBridge Pricing: Amazon EventBridge pricing
- AWS Lambda Pricing: AWS Lambda pricing
The 1 MB limit is a useful correction to years of forced indirection. Use it to simplify event-driven systems where the context is bounded and immediately useful. Keep S3 pointers for data that deserves storage semantics, governance, reuse, or a longer life than one event delivery.
The real win is architectural choice. Before, the platform forced a pointer pattern more often than the domain did. Now the domain can decide: direct rich event for short-lived context, claim check for governed data, and metrics to prove the payload budget stays honest.
Explore more like this

Golden AMI Pipelines with EC2 Image Builder and AWS CDK L2 Constructs
An EC2 Image Builder component is immutable. Change one line and you need a new version. The recipe referencing that component is immutable too, and the pipeline references the recipe....

CloudFormation Pre-Deployment Validation: Safer CDK and Stack Operations
CloudFormation now runs pre-deployment validation automatically on every CreateStack and UpdateStack operation, not only while creating change sets. A malformed property or resource-name collision can fail before AWS provisions or...


Comments