Docker Model Runner and Open WebUI: Local AI Infrastructure That DevOps Teams Can Actually Operate

Local AI stopped being a weekend toy when developer workstations started handling private code, tickets, logs, and architecture notes. Docker Model Runner plus Open WebUI is interesting because it wraps local model serving in tools platform teams already understand: Docker Engine, Docker Desktop, Compose, ports, volumes, and container lifecycle.
That is the useful angle for an engineering article. The feature is not interesting because a vendor shipped a checkbox. It is interesting because it changes how a team investigates, rolls out, audits, or operates a system when nobody has time for a research project during an incident. For adjacent background, keep these BitsLovers guides nearby: Docker Hardened Images and container trust, Docker sandboxes and microVM isolation, managed agent choices on AWS, AI coding tools for DevOps, and runtime container security.
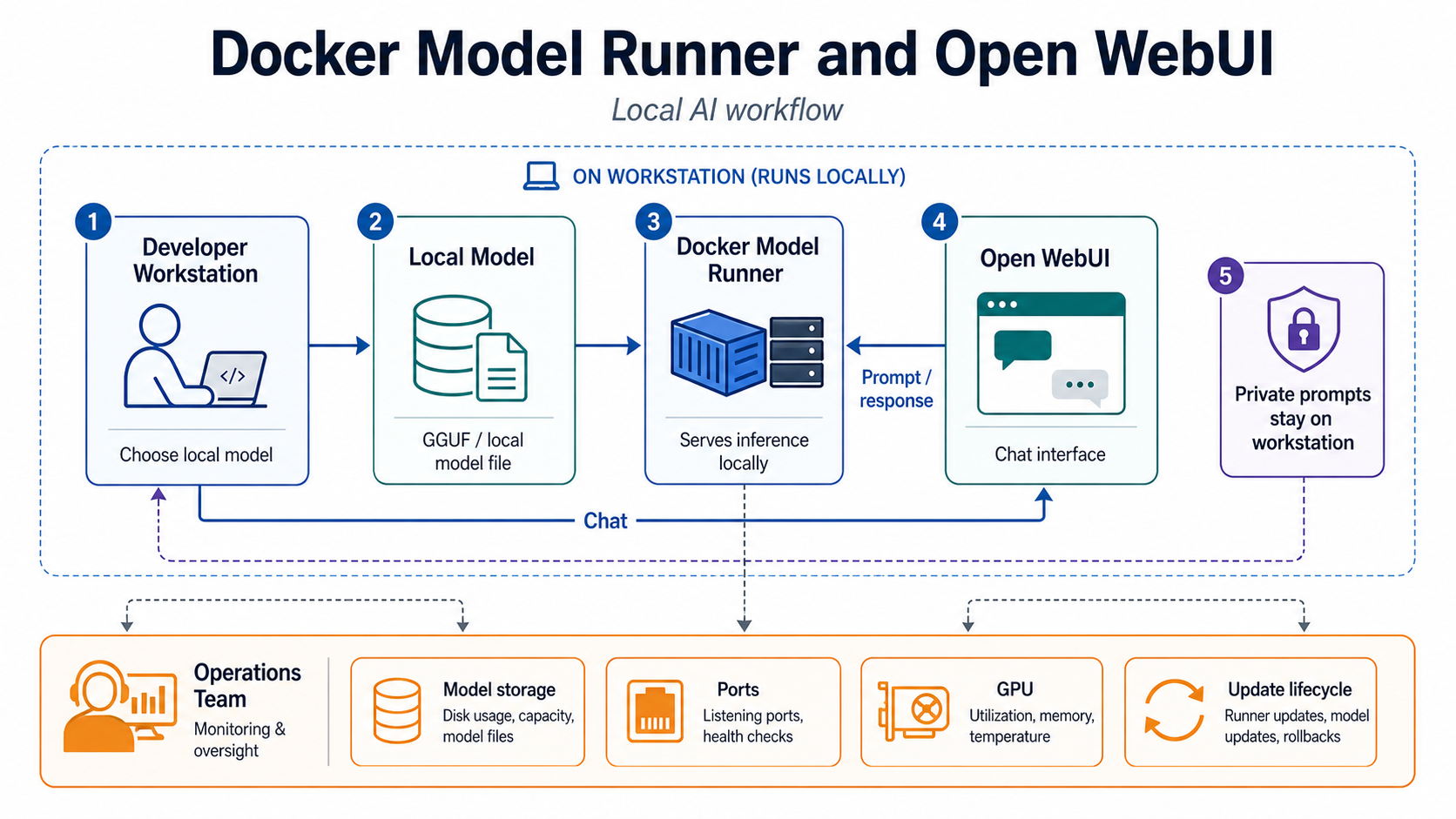
The workflow above is the shape I would use in a platform review. Start with the thing that changed, connect it to an owner and a control, then decide where the operational evidence lands. If the evidence is not searchable during an incident, the architecture is still mostly hope.
What Changed
- Docker announced zero-configuration Open WebUI integration with Docker Model Runner in February 2026.
- Open WebUI detects Docker Model Runner at localhost:12434 when TCP access is enabled.
- Docker Model Runner can expose OpenAI-compatible APIs and manage local models as Docker-managed assets.
- Docker Engine on Linux supports CPU, NVIDIA CUDA, AMD ROCm, and Vulkan backends depending on the runner.
- Docker docs list NVIDIA driver 575.57.08 or newer for Docker Engine Linux GPU support.
The first mistake is to treat this as a product-tour post. Product tours age badly. The durable question is narrower: what new operating move does this unlock, what new risk does it introduce, and where should a real team draw the boundary?
The Old Failure Mode
The old local model setup was a pile of one-off services. One developer ran Ollama, another ran llama.cpp, a third used a cloud API, and nobody knew which prompts or files left the laptop. Local AI was private in theory but unmanaged in practice.
The human cost matters here. A senior engineer can work around weak platform design by remembering where the logs, policies, dashboards, or state files live. A team cannot scale that memory. Once there are three shifts of on-call coverage, multiple application owners, and several environments, undocumented operator knowledge becomes a reliability risk.
The Operating Model I Would Use
- Run Docker Model Runner as the local inference runtime and treat it like a developer infrastructure dependency.
- Run Open WebUI as the interface layer with a persistent volume for conversations and settings.
- Keep access bound to localhost unless there is a deliberate team-hosted deployment with authentication.
- Pin model names and versions in documentation so teams can reproduce behavior during reviews.
- Add policy around what data can be uploaded to local models even when no cloud API is involved.
This model is intentionally boring. Boring is good when the work touches production. The job is not to prove that the newest feature works in a demo account. The job is to make sure it still works after a rushed deployment, a partial rollback, a permission change, and a 3 AM incident where the person responding did not build the system.
The Numbers That Shape The Design
| Fact | Number or boundary | Why it matters |
|---|---|---|
| Default DMR TCP port | 12434 | This is the integration point Open WebUI expects. |
| Open WebUI container port | 3000:8080 in Docker’s quick example | The UI stays a normal container service. |
| Docker Desktop TCP command | docker desktop enable model-runner –tcp | Desktop users must expose the runtime for Open WebUI. |
| Linux NVIDIA driver | 575.57.08 or newer | GPU acceleration has a real host prerequisite. |
| Docker Engine port | 12434 by default | Firewall and localhost assumptions need review. |
| API shape | OpenAI-compatible endpoints | Existing tools can connect with fewer custom adapters. |
These numbers are not trivia. They decide how far you can push the pattern before it becomes noisy, expensive, or dangerous. A limit, a price, or a support boundary should change the architecture. If it does not, the team probably has not decided what the number means yet.
Practical Setup Pattern
The first implementation should be small enough to throw away. I would start with one service, one environment, one owner, and one rollback path. Then I would make the pattern repeatable.
docker desktop enable model-runner --tcp
docker run -p 3000:8080 openwebui/open-webui
curl http://localhost:12434/api/tags
docker model install-runner --gpu auto
Do not copy these commands into production without changing names, ARNs, Regions, retention, and IAM scope. They are here to make the moving parts concrete. The real work is deciding which role may run the command, which account owns the evidence, and how the next engineer proves the control still works.
Architecture Review Checklist
| Review question | Good answer | Bad answer |
|---|---|---|
| Who owns the control? | A named team and escalation path | Everyone on the platform team |
| What is the rollback? | A documented command or config revert | Open the console and click around |
| What is the cost driver? | A measurable unit such as scanned GB, data events, instances, or replicas | We will watch the bill |
| What breaks if metadata is wrong? | The blast radius is known and tested | Nobody knows until an incident |
| How is drift detected? | CI, policy, scheduled audit, or deployment automation | Manual review once a quarter |
| What proof exists? | Logs, metrics, reports, or API output linked from the runbook | A screenshot in a chat thread |
The checklist is deliberately practical. It turns a launch announcement into a production decision. A good platform team should be able to answer those six questions before adopting anything account-wide.
Security, Cost, And Reliability Guardrails
Security guardrails start with least privilege, but they do not end there. The control should be visible in CloudTrail or an equivalent audit path. The resource should have owner metadata. Any generated evidence should land somewhere the security or platform team can query after the application team has moved on.
Cost guardrails need a unit. For some topics that unit is data scanned. For others it is data events delivered, GPU instances running, policy evaluation volume, or endpoint replicas. The unit matters because a dashboard labeled “cost” does not help during design review. A design review needs a sentence like this: “If we enable this on every production bus, the cost scales with event volume, so we will start with these three buses and review the first seven days of usage.”
Reliability guardrails are about failure behavior. If the new control fails closed, deployments may stop. If it fails open, evidence may be missing. If it falls back to a lower-quality path, latency or accuracy may change. Write that down. The most expensive incidents often come from controls that behaved exactly as configured but not as imagined.
Gotchas The Vendor Page Will Not Emphasize Enough
- Local does not mean risk-free. The model, UI, browser extensions, downloaded files, and host filesystem still form a data handling path.
- Model availability is not the same as model quality. A local model that runs fast may still be wrong for security review or incident work.
- GPU support is host-specific. Linux, Windows, Apple Silicon, NVIDIA, AMD, and Vulkan paths do not behave identically.
- Open WebUI should not become an unauthenticated shared service on a corporate network because someone exposed port 3000.
None of these gotchas make the feature bad. They make it real. The difference between a lab demo and a production platform is that production has old resources, odd exceptions, permissions nobody wants to touch, and dashboards that were built before the current team existed.
Decision Matrix
| Choice | Use it when | Reason |
|---|---|---|
| Use DMR plus Open WebUI | private code review, local experimentation, offline demos, controlled teams | The operational model is familiar. |
| Use Ollama directly | simple single-user CLI workflows | Less moving parts if the UI is not needed. |
| Use managed APIs | best model quality, enterprise controls, support commitments | Cloud AI still wins many production workflows. |
| Use isolated sandboxes | untrusted agent execution | Model serving is not the same as safe tool execution. |
My bias is to adopt narrowly first. The fastest way to ruin a good platform feature is to make it mandatory before the team knows the failure modes. The second fastest way is to leave it optional forever. Treat the first rollout as a test of the operating model, not the service announcement.
Rollout Plan
- Pick one production-like environment where the blast radius is real but controlled.
- Write down the owner, rollback path, alert owner, expected cost driver, and failure signal before enabling anything.
- Run a narrow test with a named service or namespace. Avoid account-wide switches on day one.
- Capture before-and-after evidence: latency, cost, error rate, query speed, finding volume, or deployment success rate.
- Convert the experiment into a runbook only after the team can explain what changed and what did not change.
- Add the final guardrail to CI, Terraform, CDK, Helm, admission policy, or account automation so the pattern survives the next deployment.
That last step is the one people skip. A pattern that depends on someone remembering to repeat it is not a platform pattern. It is a good intention with a half-life.
What To Measure
- time to first useful answer during an incident
- number of manual console clicks removed from the workflow
- new AWS spend created by the control
- false-positive or false-scope rate
- percentage of resources with correct owner and environment tags
- rollback time when the feature causes noise or failure
The right metric depends on the post topic, but every useful rollout should make one thing measurably better. If it does not reduce investigation time, reduce risky access, improve deployment success, improve capacity survival, or reduce manual work, it may still be interesting, but it is not yet worth standardizing.
When I Would Not Use It
I would not use this pattern as a blanket default on day one. I would also avoid it when the team cannot name an owner, cannot explain the pricing unit, cannot test the rollback, or cannot prove that the metadata behind the decision is accurate. In those cases, the responsible move is to fix the operating model first.
There is also a trust boundary to respect. New visibility often exposes new sensitive information: service names, owners, dependency graphs, customer identifiers, event payload patterns, model choices, policy exceptions, or network paths. Treat that metadata like production data. It can help an operator; it can also help an attacker.
A Production Design That Would Hold Up
The production version of this pattern starts with a boundary, not a tool. The boundary might be an account, an event bus, a Kubernetes namespace, a model endpoint, a policy package, a Docker workstation profile, or a public network listener. Whatever it is, write it down in a way that another engineer can inspect without knowing the backstory.
For Docker Model Runner, I would make that boundary visible in three places. First, the infrastructure code should show the resource, owner, and environment. Second, the runtime evidence should show that the control is active. Third, the runbook should explain what a responder does when the control is noisy, missing, or blocking legitimate work. That sounds procedural, but it is the difference between an announcement-driven adoption and a platform capability.
The evidence also needs a retention decision. Some evidence is only useful for live troubleshooting. Some evidence is needed for audit. Some evidence contains sensitive metadata and should not be available to every developer by default. Do not wait until the first incident to decide which bucket, log group, dashboard, policy report, or service catalog page is the source of truth.
The strongest design is boring in the right places. It should use a naming convention that survives copy and paste. It should include an owner tag or equivalent ownership field. It should avoid global permissions unless there is a reason. It should make deletion and rollback possible without an archaeological dig through old tickets.
The launch fact that matters here is Default DMR TCP port: 12434. That is the calendar signal. The design signal is Open WebUI container port: 3000:8080 in Docker’s quick example. Those are different things. The calendar tells you when a capability exists. The design signal tells you where the capability should sit in your operating model.
The Week-Two Failure Modes
Week one usually looks good. The demo works, the new image renders, the query returns data, the endpoint reaches service, the policy test passes, or the security finding shows up. Week two is where the platform truth appears.
The first week-two failure is metadata drift. A team copies a Terraform module but changes only half the tags. A namespace is renamed. A policy exception gets added for a release and never removed. An endpoint falls back to a smaller instance type and nobody notices that latency moved from acceptable to barely tolerable. A developer exposes a local AI UI beyond localhost because it made a demo easier. Each individual mistake looks small. Together they turn a good pattern into operational folklore.
The second failure is false confidence. Local does not mean risk-free. The model, UI, browser extensions, downloaded files, and host filesystem still form a data handling path. This is why a rollout should include negative tests. Remove a tag. Publish an event from the wrong role. Try a policy fixture that should fail. Start the endpoint with an unavailable preferred instance. Create a listener that should trigger a security review. A control that has never been forced to fail has not been validated; it has only been observed working once.
The third failure is cost invisibility. Model availability is not the same as model quality. A local model that runs fast may still be wrong for security review or incident work. If the pricing unit is scanned data, delivered data events, endpoint instances, policy evaluations, or inspected traffic, the runbook should name that unit directly. A graph with no cost owner is not mature. A log query with no time-window discipline is not mature. A security control that sends every byte to the most expensive destination is not mature either.
The fourth failure is ownership ambiguity. A platform team may install the control, but application teams create the workload shape that makes the control useful or noisy. If ownership is unclear, every exception becomes a negotiation. Decide in advance who can grant exceptions, who reviews them, and when they expire.
The Review Conversation I Would Want
In a real design review, I would not ask “should we use Docker Model Runner?” That question is too broad. I would ask a smaller set of questions.
What production problem are we solving? The answer should be sharper than “better visibility” or “more security.” It should say something like: reduce incident log selection from ten minutes to one minute, prove who published to a critical event bus, survive GPU capacity pressure without a failed deployment, move away from legacy policy APIs before the removal window, or prevent public proxy abuse from becoming a billing and reputation incident.
What is the first measurable outcome? A good first outcome might be a runbook that no longer needs manual console selection, a CloudTrail query that identifies a producer role, a graph that shows an owner for every production dependency, a Kyverno test suite that blocks bad fixtures, or a flow-log query that finds unusual proxy egress. If the outcome is not measurable, the rollout will become a mood.
Who is allowed to change the boundary? This is the question that catches weak designs. If every developer can change the tags, bus policies, endpoint pools, policy exceptions, model runner exposure, or proxy listener behavior without review, the control is softer than it looks. Automation can help, but only when the rule is clear enough to automate.
What does rollback mean? For Docker Model Runner, rollback should not mean deleting the whole stack. It may mean disabling a selector, removing a data event selector, reverting a policy to audit mode, pinning an endpoint to a known instance type, closing a public listener, or detaching a workflow from the production path. Rollback is a design artifact. It should exist before the first deploy.
First Thirty Minutes Runbook
The first thirty minutes of an incident decide whether a new control helps or becomes one more confusing system. I would keep the runbook short enough to read under pressure.
Minute zero to five: confirm scope. Identify the affected account, service, cluster, endpoint, policy, event bus, or network boundary. Do not start with a global search unless the incident is global. Narrow first. If the feature uses metadata, verify the metadata before trusting the result.
Minute five to ten: collect evidence from the system of record. That might be CloudWatch Logs Insights, CloudTrail, HCP Terraform, Kubernetes metrics, SageMaker endpoint description, SPIRE entries, Kyverno policy reports, Docker runtime state, VPC Flow Logs, GuardDuty, or Security Hub. Copy the query or command output into the incident record. Screenshots are weaker than text evidence because they are harder to diff and search.
Minute ten to twenty: decide whether the control is diagnosing, mitigating, or causing the issue. Those are different modes. A CloudTrail data event helps diagnose. A policy engine may mitigate or block. A fallback instance pool may keep service alive but change latency. A network control may stop abuse but also interrupt a legitimate integration. Name the mode before acting.
Minute twenty to thirty: choose the smallest reversible action. Narrow the query, disable the bad route, remove the bad tag, revoke the producer permission, switch policy to audit, scale the endpoint, rotate the credential, or isolate the listener. Avoid broad account-wide changes unless the risk is already account-wide.
After the incident, add one fixture, one query, one dashboard panel, or one policy test that would have made the first ten minutes easier. That is how the system improves without a giant postmortem project.
Governance That Does Not Rot
Governance fails when it depends on reminders. A quarterly review that asks every team to check every setting is not governance; it is a calendar ritual. Durable governance is closer to a compiler. It checks the same rule every time, gives a useful error, and keeps doing that after the original author leaves.
For this topic, the useful governance layer usually has four parts. The first is an infrastructure default. New resources should get the right tags, retention, policy mode, endpoint pool, or network boundary by default. The second is a validation step in CI or admission control. The third is runtime detection for things that bypass CI. The fourth is an exception process that is explicit, short-lived, and searchable.
The exception process deserves more attention than it usually gets. Every serious platform needs exceptions. The question is whether exceptions are visible debt or invisible decay. A good exception record names the owner, reason, expiry, reviewer, and compensating control. A bad exception is a comment in a pull request from three months ago.
This is where Docker Desktop TCP command matters: docker desktop enable model-runner –tcp. It is not just a fact to quote. It is a boundary to encode in the governance process. If the capability is region-limited, preview-limited, type-limited, beta, alpha, cost-sensitive, or exposed through a specific API, the governance should reflect that exact boundary.
A Strong Default Recommendation
My default recommendation is use dmr plus open webui when private code review, local experimentation, offline demos, controlled teams. The reason is simple: The operational model is familiar. But I would not turn that into a universal mandate. Use the first rollout to prove the operating model, then make the pattern a default only for the workloads that match the evidence.
The counter-recommendation matters too: use isolated sandboxes when untrusted agent execution. Model serving is not the same as safe tool execution. A mature platform team can say no to a good tool when the timing, ownership, or failure mode is wrong. That is not resistance. That is engineering.
The article is worth sharing only if it helps somebody make a decision. For Docker Model Runner, the decision is not whether the feature is cool. It is whether your team can connect the feature to ownership, evidence, cost, rollback, and a runbook that still works when the person who wrote it is asleep.
Final Production Checklist
Before I would call Docker Model Runner production-ready, I would expect eight plain pieces of evidence. There should be an owner, and that owner should be a team, not a person. There should be a rollback command or configuration change that has been tested outside production. There should be a cost note that names the billing unit. There should be an alert or dashboard that proves the control is alive. There should be at least one negative test showing what happens when the control blocks, misses, or falls back. There should be a documented exception process with expiry. There should be an internal link from the service catalog, runbook, or platform docs so responders can find the pattern. And there should be one scheduled review that checks whether the assumptions are still true after the first month.
That sounds like more work than turning on a feature. It is. But this is the work that makes a feature worth sharing with a serious engineering team. Vendor pages explain what is possible. Platform articles should explain what survives contact with production.
The Bottom Line
The useful version of Docker Model Runner is not “turn it on.” It is a small, owner-aware, measured rollout that makes production easier to operate after the launch-day excitement is gone.
Sources
Explore more like this

Terraform State Locking with S3 and DynamoDB in 2026
The moment two engineers run terraform apply at the same time without state locking, you have a race condition that can corrupt your entire infrastructure state. Both processes read the...

GitLab CI Environments and Review Apps in 2026
Review apps changed how my team does code review. Instead of reading diffs, reviewers click a link and see the actual change running. The designer can verify spacing on the...


Comments