Common Issues with AWS Health Check [How to avoid big problems]
![Common Issues with AWS Health Check [How to avoid big problems]](/wp-content/uploads/sites/5/2022/06/Common-Issues-with-Health-Check.png)
Common Issues with AWS Health Check
You’ve got an EC2 instance that’s clearly struggling. The app isn’t responding right. But your Auto Scaling Group just sits there, not replacing it. Sound familiar? I’ve helped a few DevOps engineers work through this, and it always takes a few minutes to track down why.
Most of the time, the instance isn’t getting replaced because of a configuration issue. Here’s what to check.
Why Your EC2 Isn’t Being Replaced
The Setup
If you have a Load Balancer of any type with an EC2 instance attached to an Auto Scaling Group, there are a couple of places where things can go wrong.
Problem: Instance isn’t being terminated
The app is clearly having a bad day, but the ASG isn’t doing anything about it.
Check This First
Open up your Auto Scaling Group from the EC2 console and look at the Details section. Find Health Checks.
Is Health Check Type set to EC2 & ELB? If it’s just set to EC2, that’s your problem. The ASG is only looking at whether the EC2 instance itself is running, not whether the load balancer considers it healthy.
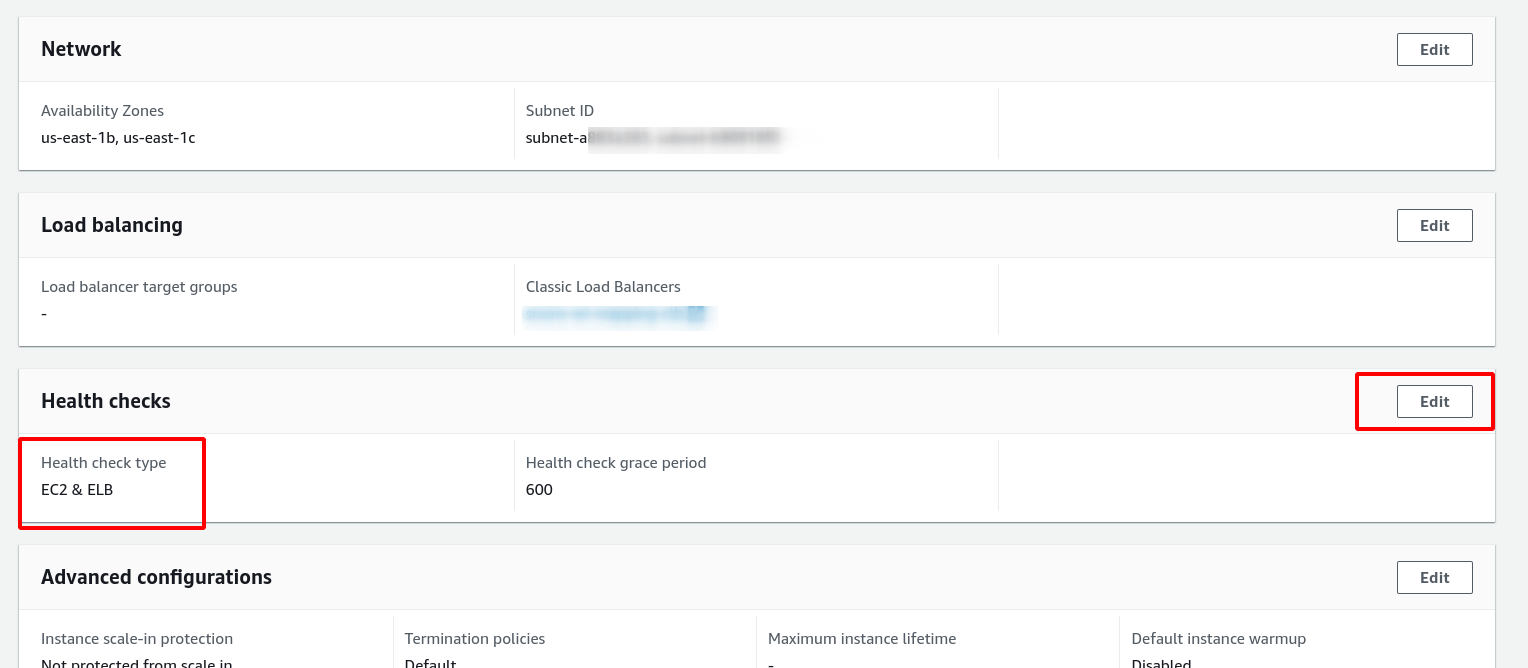
Change it to EC2 & ELB and save. Now the ASG will actually care what the load balancer thinks.
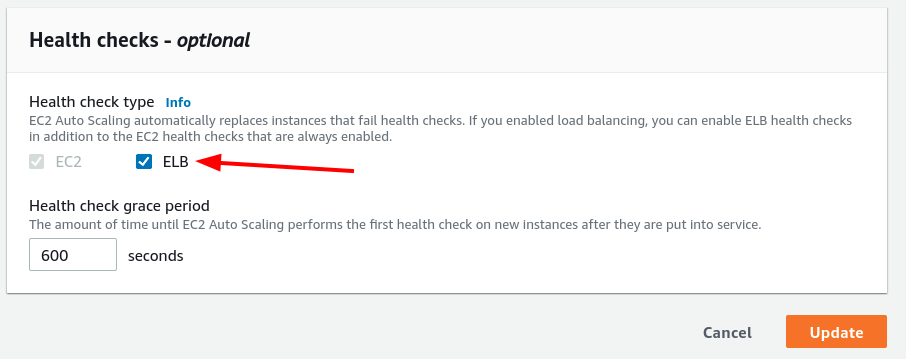
Still Not Replacing? Check the Load Balancer Settings
Okay, so you’ve got the health check type set correctly. But the instance still isn’t getting terminated when things go sideways. Time to look at the load balancer configuration itself.
The Health Check lives in the Target Group if you’re using an Application Load Balancer or Network Load Balancer. For Classic Load Balancers, it’s configured directly on the balancer.
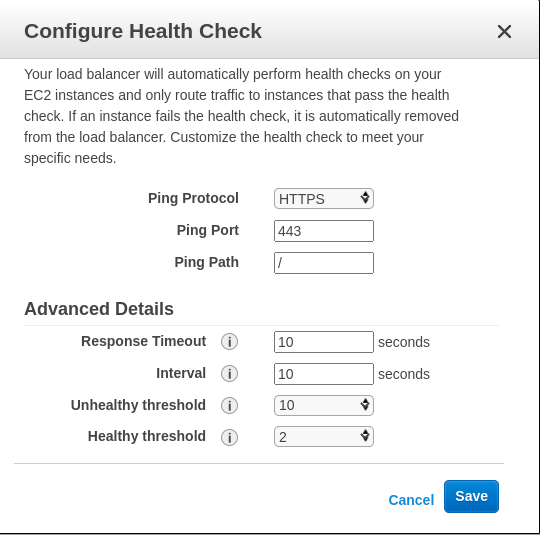
Classic Load Balancer
Application or Network Load Balancer
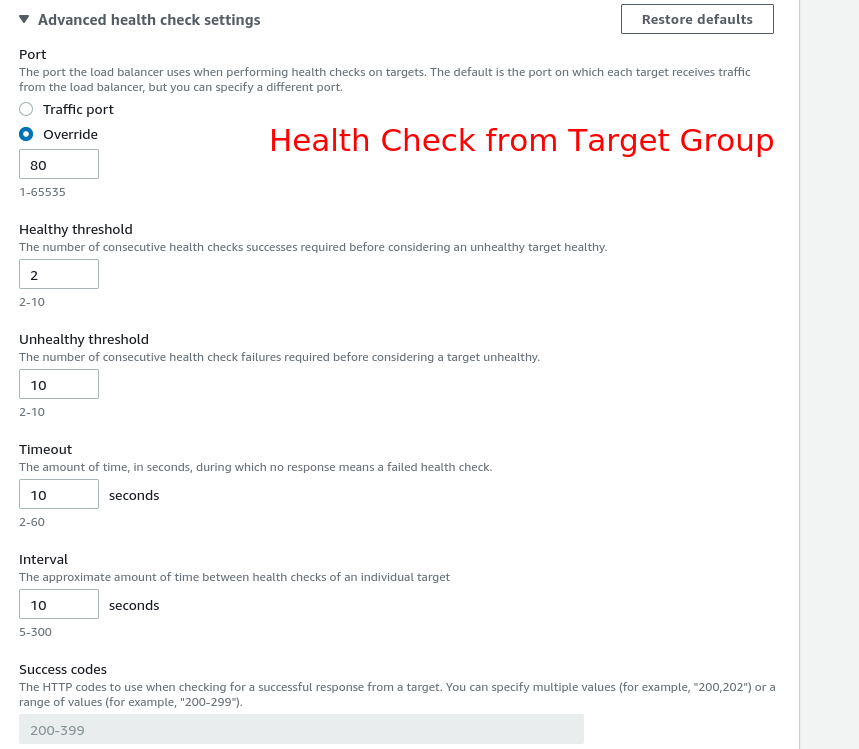
Here’s what each setting does:
Response Timeout
How long the load balancer waits for a response from the health check endpoint. In seconds.
HealthCheck Interval
How often to check each instance. Also in seconds.
Unhealthy Threshold
How many consecutive failed health checks before the instance gets marked unhealthy. Not how many failures total, consecutive.
Healthy Threshold
How many consecutive successful checks before marking an instance healthy again.
Why This Matters: An Example
Let’s say you’ve configured things this way:
- Unhealthy Threshold = 10
- HealthCheck Interval = 10
- Response Timeout = 10
Here’s the math: the instance won’t be marked unhealthy until 10 failures, each taking up to 10 seconds (timeout) plus the interval. That’s potentially 100 seconds per attempt, times 10 failures. You’re looking at nearly 17 minutes before anything happens.
Now add in a Healthy Threshold of 2. Your app is basically dead, failing 9 out of 10 requests. But that one successful response? It resets the counter. So even though your service is in bad shape, the ASG thinks everything is fine because it got a 200 on the last check.
The instance only gets replaced after 10 consecutive failures with no successful response in between.
Finding the Right Values
There’s no universal answer here. Different apps behave differently. A simple health endpoint that returns 200 from a basic process is easy to tune. A complex application with database connections, cache hits, and external API calls needs more thought.
For new applications, I usually run load tests and see what happens. Simulate high traffic, force some failures, watch how the health check behaves. Take notes. Adjust the values based on what you see.
You want the instance marked unhealthy fast enough to matter, but not so fast that a temporary hiccup causes a cascade of replacements.
Application-Level Health Checks
If you’re running an application that needs deeper inspection, consider implementing a proper health check endpoint that tests the actual functionality. Don’t just check if the process is running. Check if it can actually do its job.
For example, your health check could:
- Verify database connectivity
- Check if the cache is accessible
- Confirm external API dependencies are reachable
This gives you more control over what “healthy” actually means for your specific use case.
Explore more like this

Aurora Serverless v2 + Bedrock: AI Database Queries in 2026
I connected Bedrock to our Aurora cluster last month. The first thing I asked it was “show me all customers who churned in Q1 but came back in Q2” —...

AWS WAF Rules Deep Dive: Rate-Based, Geo, and Custom Rules
WAF is one of those services where the default managed rules get you 80% of the way there. The last 20% is where it gets interesting.


Comments