Testing Step Functions in CI/CD with the Enhanced TestState API

On March 22, 2026, the AWS Compute Blog published a practical guide for the enhanced Step Functions TestState API. The important part is not the API name. The important part is what it changes in a delivery pipeline: teams can validate individual states, mocked service integrations, Map and Parallel behavior, retry paths, callback context, and complete workflow paths before deploying the state machine into an AWS account.
That is a big shift for Step Functions. For a long time, state machines were easy to visualize and hard to test with the same discipline engineers expect from application code. You could lint Amazon States Language, deploy into a dev account, run integration tests, and hope your mocks matched production. The enhanced TestState API makes smaller tests possible.
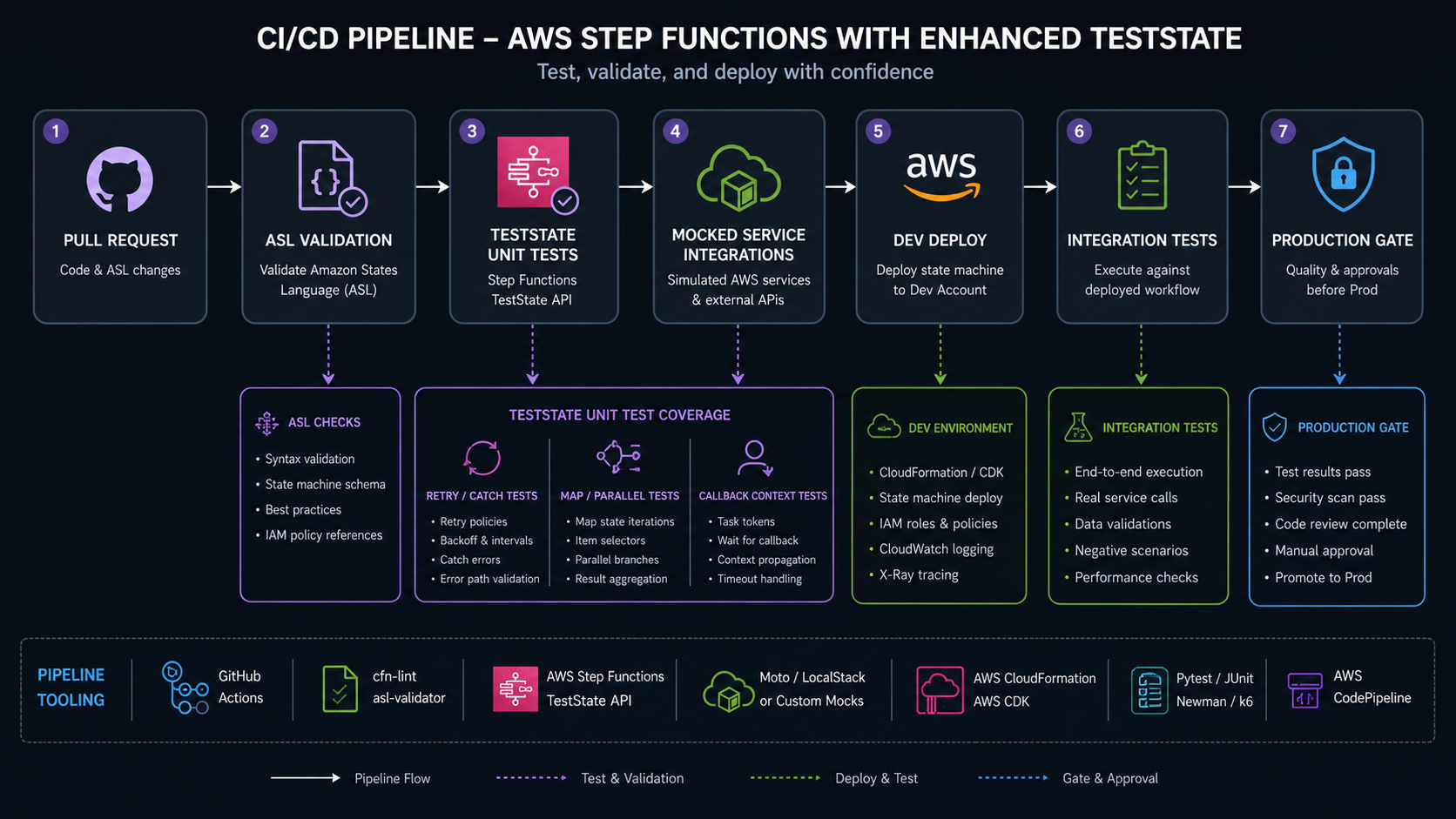
This does not mean every Step Functions test should run locally. It means your test pyramid can finally have a useful bottom layer. Unit-test state input/output behavior. Mock expensive or unavailable integrations. Simulate retry and catch paths. Then run fewer, better integration tests after deployment.
What TestState Actually Tests
The Step Functions API reference says TestState accepts the definition of a single state and executes it. You can test a state without creating a state machine or updating an existing one. The API supports testing input and output processing, AWS service integration request and response behavior, and HTTP Task request and response behavior.
That sounds narrow until you look at the state types and the enhanced behavior. The docs list support for Task states except Activity, Pass, Wait, Choice, Succeed, and Fail. The AWS Compute Blog adds the new testing surface engineers actually care about: mocked responses, actual AWS service integrations, Map and Parallel states, error simulation, retry mechanisms, context object validation, and detailed inspection metadata.
The short version:
| Test target | What you can validate | Why it matters |
|---|---|---|
| Pass and Choice states | JSONPath/JSONata transforms and branching | Most workflow bugs are data-shape bugs |
| Task integrations | Request shape, response shape, and error paths | Bad service parameters fail before deployment |
| Retry and Catch | Retry count, backoff behavior, catch selection | Failure behavior becomes testable |
| Map states | Item processing, tolerated failure behavior, item selector output | Bulk processing stops being a blind spot |
| Parallel states | Branch output and error handling | Multi-branch state machines are easier to review |
| Callback patterns | Context object and task token handling | Human approval workflows can be tested |
| Complete paths | Chained state execution in a test harness | CI can exercise business paths without full deploy |
This matters if you treat Step Functions as production code. A state machine that processes orders, payments, claims, incident remediation, or AI agent actions deserves tests. A screenshot of the workflow graph is not enough.
BitsLovers recently compared workflow ownership in Lambda Durable Functions versus Step Functions. TestState strengthens the Step Functions side of that decision. If the state machine is the architecture boundary, it needs a delivery pipeline that catches bad state transitions before production.
The Old Testing Problem
Step Functions had three common testing patterns before this improvement.
The first was static validation. Teams checked that the Amazon States Language was valid JSON or YAML, used sam validate, and maybe ran a custom schema check. This caught syntax problems, not business behavior.
The second was dev-account integration testing. Deploy the state machine, run a test execution, inspect CloudWatch logs, and tear it down later. This is valuable but slow. It also requires IAM permissions, live service dependencies, deployed Lambda functions, and cleanup.
The third was hand-rolled mocking. Teams created Python or TypeScript test harnesses that interpreted parts of the state machine definition. This can work for simple Choice states. It gets fragile when service integrations, JSONata, callbacks, Map states, and retry behavior enter the picture.
The enhanced TestState API gives teams a better middle layer.
| Testing layer | Keep it? | What it should catch |
|---|---|---|
| Static validation | Yes | Invalid ASL, missing fields, policy mistakes |
| TestState unit tests | Yes | State data flow, mocks, retries, catches, branches |
| LocalStack isolated tests | Optional | Local network-isolated tests with TestState endpoint |
| Deployed integration tests | Yes | IAM, service behavior, real permissions, real limits |
| Production canaries | Yes | Live dependency regressions and data drift |
Do not delete integration tests. TestState does not prove that your production IAM role can call DynamoDB, that a Lambda alias exists, or that a downstream API is healthy. It proves the state logic and integration request/response behavior earlier.
A Repository Structure That Works
For a serious Step Functions project, keep the state machine definition close to tests. Do not bury it inside a generated CloudFormation template where tests have to scrape it back out.
One practical layout:
workflow/
order-processing.asl.json
fragments/
validation-task.json
approval-callback.json
tests/
test_order_happy_path.py
test_order_retry_paths.py
test_order_map_tolerance.py
fixtures/
sample_order.json
invalid_order.json
template.yaml
pyproject.toml
The ASL definition is source. The SAM or CDK template references it. Tests load it directly. This is easier to reason about than generating ASL during deployment and then trying to test the generated artifact after the fact.
If you use CDK, synthesize the state machine definition in CI and test the synthesized artifact before deployment. The key rule is simple: test the same definition you deploy.
Building A Thin TestState Runner
The AWS blog shows a pytest-based approach using fixtures and method chaining. You do not need a large framework to start. You need a small runner that loads a state definition, calls test_state, captures inspection data, and gives tests readable assertions.
Here is the shape.
import json
import boto3
from pathlib import Path
class TestStateRunner:
def __init__(self, definition_path: str, role_arn: str, endpoint_url=None):
self.definition = json.loads(Path(definition_path).read_text())
self.role_arn = role_arn
self.client = boto3.client("stepfunctions", endpoint_url=endpoint_url)
def state_definition(self, state_name: str) -> str:
state = self.definition["States"][state_name]
return json.dumps({
"StartAt": state_name,
"States": {state_name: state},
})
def execute(self, state_name: str, payload: dict, mock=None, context=None, state_configuration=None):
response = self.client.test_state(
definition=self.state_definition(state_name),
roleArn=self.role_arn,
input=json.dumps(payload),
inspectionLevel="TRACE",
mock=mock or {},
context=json.dumps(context) if context else None,
stateConfiguration=state_configuration or {},
stateName=state_name,
)
self.response = response
return response
Production-quality code should omit None fields before calling the API because botocore does not accept nulls for every parameter. It should also handle LocalStack endpoint configuration, region, credentials, and response normalization. The point is the boundary. Tests should not duplicate AWS behavior. They should call the real TestState interface.
The TestState API can run for up to five minutes. If a state execution exceeds that, it fails with States.Timeout. That is long enough for state-level tests and short enough to prevent a broken test from becoming an accidental workflow run.
IAM For Workflow Tests
TestState needs a role ARN. That role should be boring and narrow. Do not point CI at the same role that production executions use unless your organization has explicitly approved that pattern. The test role should be allowed to exercise only the states, services, and mock paths required by the test suite.
There are two common setups:
| Setup | Good for | Risk |
|---|---|---|
| Mock-only CI role | Pull-request validation with no live service writes | Can miss IAM and integration mistakes |
| Dev-account integration role | Post-merge integration test against deployed services | Can mutate real dev data if tests are sloppy |
For pull requests from branches, I prefer mock-only tests plus static IAM checks. After merge, run integration tests in a dev account with short-lived credentials. If the workflow performs destructive actions, create test-only resources and enforce resource tags in the role policy.
Example policy boundary for a dev test role:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "lambda:InvokeFunction",
"Resource": "arn:aws:lambda:us-east-1:123456789012:function:orders-dev-*"
},
{
"Effect": "Allow",
"Action": [
"dynamodb:GetItem",
"dynamodb:PutItem",
"dynamodb:UpdateItem"
],
"Resource": "arn:aws:dynamodb:us-east-1:123456789012:table/orders-dev-*"
}
]
}
The exact policy depends on your workflow. The principle is stable: tests should have enough permission to prove behavior and not enough permission to damage unrelated resources.
JSONPath, JSONata, And Data Shape Bugs
Step Functions bugs often come from data shaping, not from service availability. A ResultPath overwrites the wrong object. A Parameters block passes the whole input instead of one field. A JSONata expression works for one fixture and fails when an optional field is missing.
These are perfect TestState cases.
| Data-shape concern | Test fixture |
|---|---|
| Missing optional customer field | Input without customer.email |
| Empty array in Map state | Input with items: [] |
| Large but valid payload | Input close to your chosen payload budget |
| Unexpected downstream response | Mock response with extra fields |
| Service error envelope | Mock response with exact error name and cause |
For every state that transforms data, save the expected output as a fixture. Do not assert only that the state succeeded. Assert the payload the next state will receive. That catches the expensive class of failures where each individual state is “green” but the workflow passes nonsense forward.
This is also where contract tests help. If another team owns the Lambda or service integration behind a Task state, agree on example input and output documents. Store them in version control. When either side changes the contract, the workflow tests should fail before deployment.
Testing A Lambda Retry Path
Retry behavior is where many workflows lie to their owners. The diagram shows a retry. The production path does something different because the error name, backoff, or catch target is wrong.
The AWS blog demonstrates testing Lambda.TooManyRequestsException and validating inspection metadata such as retry backoff interval, retry index, and catch index. That is exactly the kind of failure-mode test CI should run.
A simplified pytest case:
def test_validate_order_retries_then_catches(runner):
throttling_error = {
"errorOutput": {
"error": "Lambda.TooManyRequestsException",
"cause": "Request rate exceeded"
}
}
response = runner.execute(
"ValidateOrder",
{"orderId": "order-retry-test"},
mock=throttling_error,
state_configuration={"retrierRetryCount": 3},
)
assert response["status"] in {"FAILED", "SUCCEEDED"}
details = response.get("inspectionData", {}).get("errorDetails", {})
assert details.get("catchIndex") == 0
The exact assertions should match your workflow. If a throttled Lambda should retry twice and then transition to ValidationFailed, assert that. If DynamoDB conditional failures should not retry, assert that too.
This is the practical value: you stop trusting the shape of the graph and start testing the failure contract.
Testing Map State Tolerance
Map states deserve their own tests. They process many items, often with partial failure tolerance. One bad threshold can silently turn a graceful degradation pattern into a full workflow failure.
The enhanced TestState API supports configuration for Map state simulation. The AWS blog describes using stateConfiguration.mapIterationFailureCount to simulate iteration failures, then inspecting tolerated failure count and tolerated failure percentage metadata.
Test this when your workflow uses any of these features:
| Map feature | Test to write | Production failure prevented |
|---|---|---|
| ItemSelector | Assert transformed item shape | Wrong per-item payload sent downstream |
| ItemBatcher | Assert batch size and structure | Unexpected batch memory or timeout failures |
| ToleratedFailureCount | Simulate one over the threshold | Full workflow failure behavior is known |
| ToleratedFailurePercentage | Test below and above threshold | Partial failure does not surprise operators |
| Distributed Map | Test state-level config and run integration separately | Unit tests catch shape, integration tests catch scale |
If the workflow drives large serverless payloads, pair this with the 1 MB Lambda, SQS, and EventBridge payload guide. Map states plus large payloads can multiply cost and memory pressure fast.
Testing Callback Context
Human approval workflows are easy to draw and easy to break. The task token is often embedded into a Lambda payload, notification, or external approval system. A small context mapping bug can leave the workflow waiting forever.
The AWS blog’s callback example builds a context object with Task.Token, Execution.Id, and State.Name, then validates that JSONata expressions processed the context correctly. That is a strong pattern for CI.
For approval states, test:
| Field | Why test it |
|---|---|
Task.Token |
The approval system must receive the token it will send back |
Execution.Id |
Operators need traceability between approval and workflow run |
State.Name |
Approval UI and logs should identify the waiting state |
| Business amount or risk field | Approval thresholds often depend on transformed input |
| Timeout path | A missing approval should move to the right failure or escalation state |
The callback path is also a security boundary. Do not leak the task token into broad logs or low-trust systems. Treat it like a capability. Anyone with the token and permission to call back can affect workflow progress.
CI/CD Pipeline Design
The AWS blog’s sample pipeline has a simple two-step shape: run the TestState API test suite with pytest, then deploy resources with SAM. That is the minimum useful pattern.
For production, I would expand the gates:
name: step-functions-ci
on:
pull_request:
push:
branches: [main]
jobs:
test-workflow:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-python@v5
with:
python-version: '3.12'
- run: pip install -r requirements-dev.txt
- run: python -m json.tool workflow/order-processing.asl.json > /dev/null
- run: pytest tests/unit -v
deploy-dev:
needs: test-workflow
if: github.ref == 'refs/heads/main'
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- run: sam build
- run: sam deploy --config-env dev --no-confirm-changeset
- run: pytest tests/integration -v
If you use OIDC for GitHub Actions, replace static AWS access keys with a role assumption flow. The AWS blog lists repository secrets such as AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY, and AWS_REGION for the sample. That is fine for a demo. In a production organization, use short-lived credentials and tight deployment roles.
A better gate sequence is:
| Gate | Runs on pull request | Runs after merge | Blocks deploy? |
|---|---|---|---|
| ASL format and schema validation | Yes | Yes | Yes |
| IAM policy diff review | Yes | Yes | Yes |
| TestState unit tests with mocks | Yes | Yes | Yes |
| LocalStack isolated tests | Optional | Optional | Usually yes |
| Dev-account integration tests | No or nightly | Yes | Yes |
| Production canary execution | No | After deploy | Rollback trigger |
This connects with the AWS Fault Injection Simulator guide. TestState catches workflow logic errors before deployment. Chaos and canary tests catch real dependency and resilience failures after deployment. You need both.
Pull Request Review Checklist
Add a workflow-specific checklist to pull requests. Reviewers are much more likely to catch subtle Step Functions defects when the expected questions are visible.
| PR question | Why it belongs in review |
|---|---|
| Did any state name change? | Running executions and alarms may depend on state names |
| Did any retry or catch rule change? | Failure behavior and cost can change silently |
| Did any payload path change? | Downstream states may receive a different shape |
| Did any service integration action change? | IAM and blast radius may change |
| Did any Map/Parallel behavior change? | Concurrency and partial failure semantics may change |
| Did tests cover the new failure path? | Happy-path-only tests are weak for orchestration |
| Did payload size grow materially? | Step Functions request limits and logging cost matter |
For teams using GitLab CI, the same idea applies. Run static validation, TestState unit tests, and integration tests as separate jobs so a reviewer can see which layer failed. BitsLovers’ GitLab CI service testing patterns are not Step Functions-specific, but the pipeline separation principle is the same: fast tests first, environment-heavy tests later.
What To Mock And What Not To Mock
Mocking is a tool. It can also make bad workflows look good.
Use mocks when you are testing state-machine logic: a Lambda returns a validation error, DynamoDB returns throttling, an approval response is accepted, a Map item fails, or a branch returns a transformed payload. Do not use mocks to claim that IAM, throughput, network reachability, KMS access, or service-specific quotas are correct.
| Concern | TestState mock | Deployed integration test |
|---|---|---|
| Choice branch selects correct next state | Yes | Optional |
Retry catches Lambda.TooManyRequestsException |
Yes | Optional |
| DynamoDB item schema is valid | Yes | Yes |
| IAM role can write to table | No | Yes |
| KMS permissions are correct | No | Yes |
| Lambda alias exists | No | Yes |
| EventBridge target receives event | No | Yes |
| Payload size stays under quota | Yes, as a unit check | Yes, with real service path |
The healthiest pipeline is honest about each layer. A mock test says, “If this service returns this error, the workflow does the right thing.” It does not say, “The service will be callable in production.”
Step Functions Limits To Keep In View
TestState improves testing, but normal Step Functions quotas still shape design. AWS Step Functions service quotas include a 1 MB maximum state machine definition size, a 1 MB maximum request size, and 1,000,000 maximum open executions per account per Region for Standard workflows. The Step Functions pricing page says Standard Workflows are charged by state transitions, retries included, and Express Workflows are charged by requests and duration.
Those numbers affect tests.
| Design fact | Test implication |
|---|---|
| 1 MB API request size | Test generated payloads before publish or execution |
| 1 MB state machine definition size | Watch generated CDK definitions and nested workflows |
| 1,000,000 open Standard executions per account/Region | Include stuck-execution alarms and cleanup runbooks |
| Retries count as state transitions in Standard | Test retry counts and cost assumptions |
| TestState can run a state for up to five minutes | Keep unit tests state-sized, not full workload-sized |
For workflow architecture patterns, the EventBridge and Step Functions guide is still the better place to decide whether an event bus, state machine, or queue should own a boundary. This article is about how to test the state machine once you have chosen it.
A Quality Checklist For Workflow Tests
Before I trust a Step Functions pipeline, I want these tests:
- At least one happy-path test that chains core states.
- One failure test per external service integration.
- One retry exhaustion test for each important retrier.
- One catch-routing test for each business error class.
- One payload-size test for the largest realistic input.
- One schema-version compatibility test.
- One callback context test if task tokens are used.
- One Map/Parallel test if bulk or branch logic is used.
- One IAM integration test after deployment.
- One canary or synthetic execution in the target environment.
This is not busywork. Step Functions often coordinates money movement, customer communication, incident response, batch processing, or infrastructure automation. The failure paths are the product.
If your workflow calls AI systems, add one more layer: freeze model-facing prompts or tool-call envelopes as test fixtures. The OpenAI on Bedrock governance guide explains why agent identity and tool boundaries matter. Step Functions can enforce those boundaries, but only if the workflow is tested like code.
Common Failure Modes I Would Simulate
Every important workflow deserves a small failure catalog. Keep it near the tests. It becomes a map of what the team believes can go wrong.
For an order workflow, simulate:
- Lambda throttling on validation.
- DynamoDB conditional check failure on idempotency.
- EventBridge publish failure after payment authorization.
- Approval callback timeout.
- Map item failure below the tolerated threshold.
- Map item failure above the tolerated threshold.
- Payload that exceeds the team’s internal size budget.
- Downstream response with a new optional field.
- Downstream response missing a field the workflow expects.
For an incident-remediation workflow, simulate:
- CloudWatch alarm data missing.
- SSM automation denied by IAM.
- ECS service update failure.
- Human rejection of a proposed remediation.
- Retry exhaustion before escalation.
The list should be boring and specific. If the test name reads like a real incident ticket, it is probably useful.
Measuring Test Quality
Do not measure workflow test quality by the number of pytest files. Measure it by the production questions those tests answer.
Useful metrics:
| Metric | Target |
|---|---|
| Critical states with at least one success test | 100% |
| External integrations with at least one failure test | 100% |
| Retry policies with exhaustion tests | 100% for payment, incident, and data-mutating paths |
| Callback states with timeout tests | 100% |
| Map or Parallel states with partial-failure tests | 100% when used |
| Largest realistic payload tested | At least one fixture near the design budget |
The table is intentionally strict. A workflow is glue between failure domains. If the tests cover only the happy path, they prove the least interesting behavior. The enhanced TestState API is useful because it lets a team make failure behavior cheap to exercise. Use that advantage.
Also keep one negative test that proves the CI gate fails. Break a fixture in a branch, confirm the job blocks deployment, and then revert the break. This sounds obvious, but many teams have “tests” that run and never assert the thing that matters.
One final signal is review speed. When tests are precise, reviewers stop arguing from memory and start reading evidence. A failed Choice assertion, a mocked throttling response, or a payload fixture diff is easier to discuss than a screenshot of a state machine and a vague comment that “the workflow should retry.”
Sources
- AWS Compute Blog: Testing Step Functions workflows: a guide to the enhanced TestState API
- AWS Step Functions API Reference: TestState
- AWS Step Functions Developer Guide: Step Functions service quotas
- AWS Step Functions Pricing: AWS Step Functions pricing
- AWS SAM documentation: sam build
- AWS SAM documentation: sam deploy
The enhanced TestState API makes Step Functions feel less like a diagram that happens to run and more like deployable software. Use it to move workflow defects left. Keep integration tests for the real cloud boundary. The combination is what makes a state machine safe to change.
Explore more like this

Golden AMI Pipelines with EC2 Image Builder and AWS CDK L2 Constructs
An EC2 Image Builder component is immutable. Change one line and you need a new version. The recipe referencing that component is immutable too, and the pipeline references the recipe....

CloudFormation Pre-Deployment Validation: Safer CDK and Stack Operations
CloudFormation now runs pre-deployment validation automatically on every CreateStack and UpdateStack operation, not only while creating change sets. A malformed property or resource-name collision can fail before AWS provisions or...


Comments