High Availability on AWS in 2026: Patterns That Actually Work
Every team building on AWS eventually asks the same question: how much availability is enough? “Five nines” (99.999%) sounds impressive — that’s only 5.26 minutes of downtime per year — but getting there is expensive. It requires fully redundant infrastructure, automated failover at every tier, and multi-region active-active deployments.
Most production systems don’t need that. 99.9% (8.7 hours per year) or 99.95% (4.4 hours per year) is the realistic target for the majority of workloads. The patterns to achieve those are well-understood, the costs are manageable, and AWS has first-class support for all of them.
Define your SLA first. Then build to meet it. Over-engineering HA is a real cost, not just a theoretical one.
The Multi-AZ Foundation
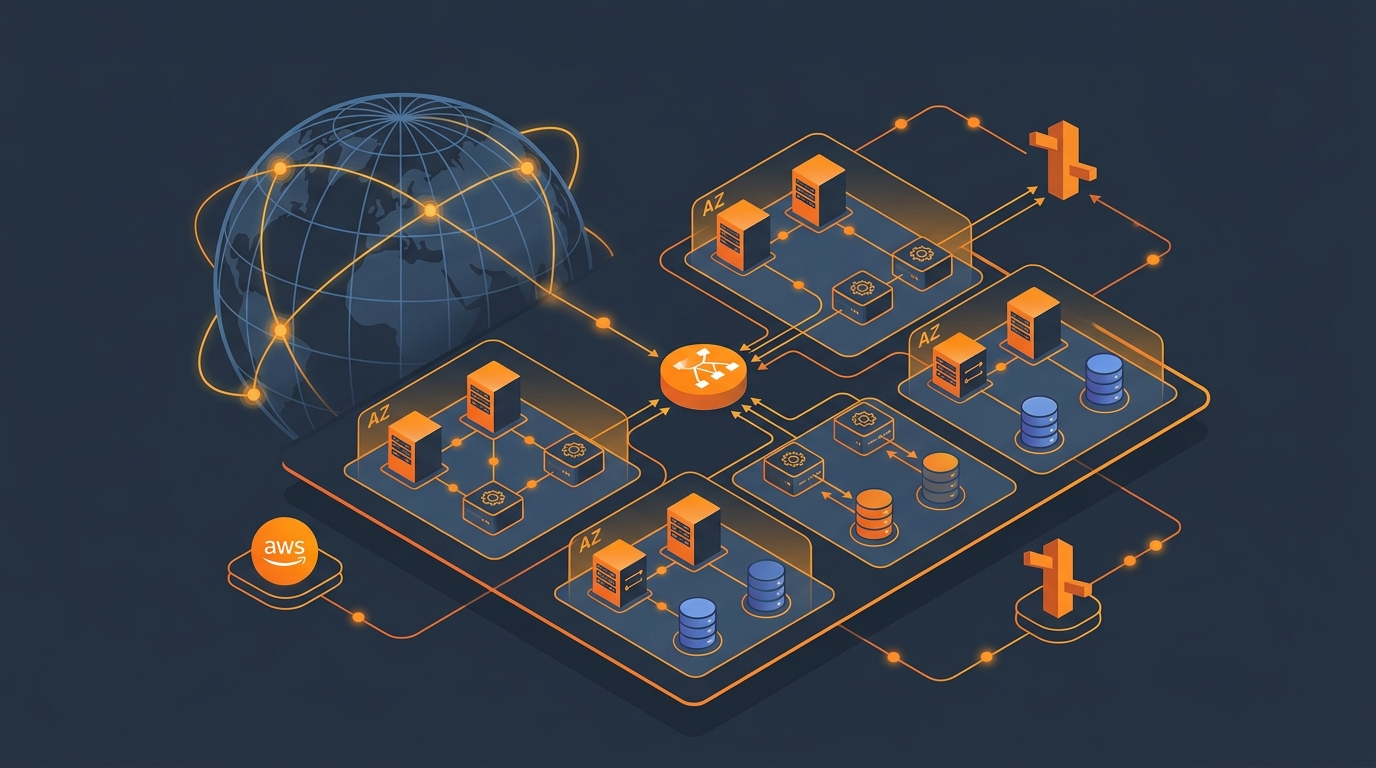
Every production AWS workload should span at least two Availability Zones. AZ failures happen — us-east-1a has gone down multiple times over the years, and no AZ is immune. Keeping your entire application in a single AZ is a single point of failure you don’t need to accept.
The standard three-tier architecture for a web application looks like this:
- Application Load Balancer across 2+ AZs — receives traffic and distributes it to healthy targets
- EC2 Auto Scaling Group (or ECS tasks) spanning 2+ AZs — your compute tier, automatically replacing failed instances
- RDS Multi-AZ — primary in one AZ, synchronous standby in a second AZ, automatic failover in 60–120 seconds
- ElastiCache with a read replica in the second AZ — so your cache layer survives an AZ loss
This is table stakes. If any tier is single-AZ, you don’t have high availability — you have a system that might survive some failures.
One thing that catches teams off guard: RDS Multi-AZ failover takes 60–120 seconds, and your application will see connection errors during that window. Your connection pooling and retry logic needs to handle this gracefully. Plan for it.
Route 53 Health Checks and DNS Failover
Route 53 health checks give you DNS-level failover, which is your last line of defense when an entire region or endpoint goes down.
A health check hits your endpoint (HTTP/HTTPS) every 30 seconds from multiple AWS locations. If the endpoint fails a threshold of consecutive checks, Route 53 marks it unhealthy and stops routing traffic to it.
Three routing policies worth knowing for HA:
Failover routing — You define a primary record and a secondary record. If the primary’s health check fails, Route 53 automatically serves the secondary. A common pattern: primary points to your ALB, secondary points to a static S3 page that tells users the service is temporarily unavailable. Not ideal, but much better than a connection timeout.
Latency-based routing — Route 53 routes each request to the region with the lowest latency for that user. Combined with health checks, traffic automatically shifts away from degraded regions.
Weighted routing — Send a percentage of traffic to each endpoint. Useful for gradual region migrations or blue-green deployments at the DNS level.
One practical tip: set your TTL low (30–60 seconds) on records backed by health checks. DNS caching in the middle will delay your failover otherwise.
ALB and Auto Scaling: The Core of EC2 HA
For EC2-based workloads, the ALB + Auto Scaling Group combination is where most of your HA work happens.
A few settings that matter in production:
Health check grace period — When Auto Scaling launches a new instance, it waits this long before evaluating the health check. If your application takes 90 seconds to boot and your grace period is 30 seconds, instances will be terminated before they’re ready. Set this to at least your P95 boot time.
Instance refresh — When you update your launch template (new AMI, updated user data), Instance Refresh performs a rolling replacement. Instances are replaced in batches, and the new instances must pass health checks before the next batch starts. Zero-downtime AMI updates with no manual effort.
Capacity rebalancing for Spot — If you’re using Spot instances, capacity rebalancing tells Auto Scaling to launch replacements proactively when AWS signals an interruption is coming. You get a new instance running before the old one is reclaimed.
Scale-in protection — Enables you to mark specific instances so Auto Scaling won’t terminate them during a scale-in event. Useful for instances running long jobs that can’t be interrupted.
A minimal Terraform block for an ALB target group with health checks:
resource "aws_lb_target_group" "app" {
name = "app-tg"
port = 8080
protocol = "HTTP"
vpc_id = var.vpc_id
target_type = "instance"
health_check {
path = "/health"
protocol = "HTTP"
interval = 30
timeout = 5
healthy_threshold = 2
unhealthy_threshold = 3
matcher = "200"
}
}
The health check endpoint (/health) should verify that the application is actually ready to serve traffic — database connection is live, cache is reachable, critical dependencies are up. A health check that just returns 200 immediately on startup is worse than no health check.
Database HA Patterns
Databases are where HA gets expensive. Three tiers to understand:
RDS Multi-AZ is the baseline. AWS maintains a synchronous standby in a second AZ. If the primary fails, Route 53 CNAME for your DB endpoint flips to the standby in 60–120 seconds. No data loss (synchronous replication). Works for most applications. The standby is not readable — it exists only for failover.
Aurora Multi-AZ is worth the upgrade for latency-sensitive reads. Aurora supports up to 15 read replicas across AZs, all accessible via the reader endpoint. Your application can spread read traffic across replicas without any custom logic. Failover is faster than RDS Multi-AZ — under 30 seconds in most cases. The Aurora storage layer is itself distributed across 3 AZs by default, which gives you durability independent of the instance tier.
Aurora Global Database is for when you need cross-region disaster recovery. Aurora replicates to secondary regions with under 1 second of replication lag. For planned failovers (maintenance, region migration), RTO is under 1 minute. For unplanned failovers, expect 1–2 minutes. RPO is near-zero. The cost is real — you’re paying for a primary cluster plus one or more secondary clusters — but for applications where regional outages are unacceptable, this is the right tool.
Match the tier to your actual SLA. Most applications are well-served by RDS Multi-AZ. Moving to Aurora Global just because it sounds more resilient is a cost you probably don’t need.
Stateless Applications Make HA Much Easier
The single biggest thing you can do to simplify HA is keep your application instances stateless. If any instance can be terminated and replaced without manual intervention, your Auto Scaling group works exactly as intended.
In practice, this means:
- Session data goes in ElastiCache, not local memory. When an instance is replaced, the new one picks up session state from the cache.
- Uploaded files go in S3, not instance storage. Instance storage is ephemeral — it disappears when the instance terminates.
- Configuration and secrets come from Parameter Store or Secrets Manager, not environment files baked into the AMI or deployed alongside code.
If your application writes anything to the local filesystem that other requests depend on, you have hidden state. Find it and move it out before you need HA to work under pressure.
Circuit Breakers and Retry Logic
ALB does not retry failed requests. If a target returns a 502 or times out, ALB returns that error to the client. Your application code and service-to-service calls need their own retry logic.
The AWS SDK has configurable retry behavior with exponential backoff built in. For HTTP calls your application makes directly, implement exponential backoff with jitter: start with a small delay, double it each retry, add randomness to prevent thundering herd behavior when many instances retry simultaneously.
For microservices architectures, circuit breakers prevent cascading failures. When service A calls service B and B is degraded, A should stop sending requests after a failure threshold — not keep piling on. AWS App Mesh supports circuit breaking at the service mesh level. Alternatively, libraries like Resilience4j (Java) or similar implement this in application code.
One failure mode that catches teams: a single slow dependency causes all threads to block waiting for it, exhausting the connection pool and taking down the calling service. Timeouts on every outbound call are not optional.
Multi-Region HA
Single-region HA handles AZ failures. Multi-region HA handles regional outages — rare, but they happen, and recovery without pre-built multi-region infrastructure can take hours.
When 99.9% in one region isn’t enough, the typical stack looks like:
- Route 53 with latency-based or failover routing between two regions, backed by health checks on each region’s ALB
- DynamoDB Global Tables for active-active multi-region NoSQL — reads and writes are accepted in any region, replication is automatic
- Aurora Global Database for active-passive SQL with fast promoted failover
- S3 Cross-Region Replication for object storage
The honest cost: you are paying for two environments. Compute, databases, data transfer, and operational overhead roughly double. Before committing to multi-region, verify that your SLA actually requires it and that your business case supports the cost.
Active-active multi-region (where both regions serve live traffic) is significantly more complex than active-passive (where the secondary region sits warm but idle). Conflict resolution for concurrent writes, data consistency across regions, and session routing all require careful design. Start with active-passive and upgrade only if your RTO requirements demand it.
Testing HA: If You Haven’t Tested It, You Don’t Know
This section matters more than most teams admit. You can build a textbook HA architecture and still have a system that fails badly in practice because the failover has never been exercised.
AWS Fault Injection Service (FIS) lets you run controlled failure experiments:
- Terminate EC2 instances — verify Auto Scaling replaces them and traffic continues
- Interrupt Spot capacity — verify capacity rebalancing kicks in before interruption
- Simulate AZ impairment — verify traffic shifts to healthy AZs
- Throttle API calls — verify your application handles dependency throttling gracefully
- Inject latency into RDS calls — verify your timeout and retry logic behaves correctly
Run these experiments in a staging environment first, then in production during low-traffic windows. Document what you expected to happen and what actually happened. The gaps between expectation and reality are the bugs in your HA design.
Scheduled chaos experiments — automated FIS runs on a regular cadence — catch regressions when someone changes a timeout, removes a health check, or deploys a change that breaks a failover path.
If your team has never run a failover drill, start there. Manually terminate an instance in production (during low traffic, with the team watching). Verify that Auto Scaling replaces it, ALB routes around it, and users see no errors. That 15-minute exercise will teach you more about your actual HA posture than any architecture diagram.
Related Posts
Explore more like this

Aurora Serverless v2 + Bedrock: AI Database Queries in 2026
I connected Bedrock to our Aurora cluster last month. The first thing I asked it was “show me all customers who churned in Q1 but came back in Q2” —...

AWS WAF Rules Deep Dive: Rate-Based, Geo, and Custom Rules
WAF is one of those services where the default managed rules get you 80% of the way there. The last 20% is where it gets interesting.


Comments