RDS PostgreSQL Blue/Green Deployment
John was working on a company project that used an RDS Postgres database. Things had been going smoothly until one day he got an email from AWS: the database server needed a major version upgrade. The catch? The upgrade required downtime, and John needed to find a way to handle it without taking the service down.
He started researching options for keeping data in sync between two databases during the switch. That’s when he found AWS DMS (Database Migration Service). It lets you replicate data from one source database to multiple targets with almost zero downtime.
So John built an automated process using DMS to keep two databases in sync in real-time. No manual intervention needed. The result: he could update the RDS instance without any service disruption.
Blue/Green Deployment
Blue/Green deployment is a DevOps technique where you run two identical production environments at the same time. You test changes in one environment (green) before pushing them to the other (blue). If something goes wrong, you switch back to the original environment.
The main benefits:
- Zero-downtime updates
- Instant rollback if something breaks
- Easy scaling up or down based on demand
- No surprises in production because you’ve already tested everything
RDS PostgreSQL Blue/Green Deployment
The Hard Part: Keeping Two Databases in Sync
The tricky part of blue/green deployment is making sure both databases stay identical. If they drift apart, you could lose or corrupt data. You need a reliable way to sync changes from one environment to the other.
Another issue: if a bug slips through during the update, rolling back takes time. You need a solid plan for handling this.
Finally, running two environments costs resources. You need to plan for scaling and make sure you have enough capacity to keep both running.
One Drawback of Amazon RDS
RDS is a managed service, which means you don’t have full control over the underlying database. When AWS sends you a deadline to upgrade, you might not have an easy way to do it without downtime.
Also, AWS sometimes removes old engine versions from the console. If you need to roll back, you might find the old version isn’t available anymore.
If you’re using RDS, plan for blue/green deployments so you can handle upgrades without taking your app offline.
Postgres Replication
PostgreSQL uses Write-Ahead Logging (WAL) to track database changes. WAL writes all changes to a log before applying them to the database itself. If the database crashes, it can recover from the WAL logs.
WAL logs live on disk and replicate across all replicas in a cluster. When a transaction commits on the primary, the changes go to an intermediate WAL log, then replay on each replica.
Postgres also has replication slots. These track which transactions have been applied on each replica, so only unapplied transactions get replayed. This makes replication more efficient.
Enabling RDS Postgres Replication
To enable replication slots on RDS Postgres, create a new parameter group and set rds.logical_replication to 1. This turns on replication slots for all databases in the instance.
Once you set this parameter, you must apply it to your database and restart the instance for the changes to take effect.
Note: this parameter increases WAL generation, so only enable it when you’re actually using logical replication.
AWS DMS
AWS Database Migration Service (DMS) is a managed service that moves data between databases. It supports PostgreSQL and uses WAL logs to replicate changes in real-time with no downtime.
With DMS, you can keep your production database in sync with replicas without manual work. It reads the WAL logs and applies changes to the target.
DMS Task Setup
Here’s how to set up a DMS task:
Replication Instance
First, create a replication instance. This is the server that manages data transfer between source and target databases. Make sure it has enough resources to handle your workload.
Keep in mind: replication instances run on EC2, so you’ll pay for compute, storage, and data transfer.
Step 1: Create a DMS Task
Go to the AWS Database Migration Service console, click Tasks, then Create Task. Give it a descriptive name.
Step 2: Configure the Source Endpoint
Pick PostgreSQL as the source, enter your database credentials, and provide the connection details (host, port, etc.).
Step 3: Configure the Target Endpoint
Do the same for the target database.
Step 4: Configure Task Settings
Set up how DMS will migrate your data. You can use logical replication slots or configure table mapping with full-load mode.
Step 5: Start Migration
Click Start Task. DMS first loads the full source database, then continuously replicates changes via WAL logs. Monitor progress in the DMS console.
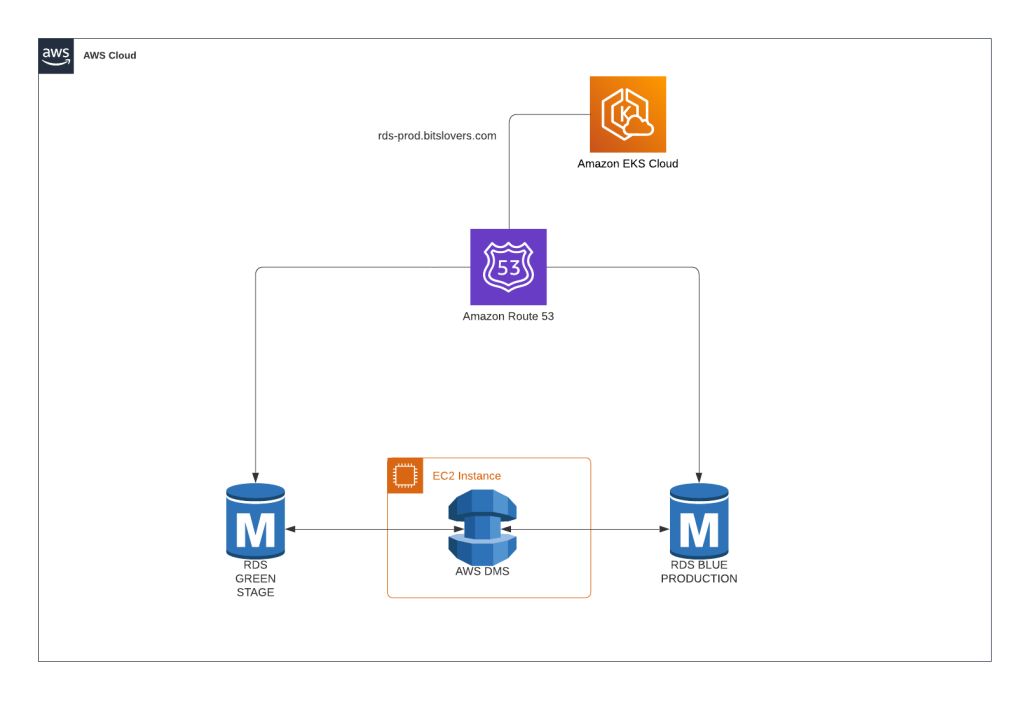
Swapping Between Blue and Green with DNS
To switch between blue and green databases, use Route 53. Create a hosted zone for your domain, then add an Alias record pointing to whichever environment you want live (blue or green).
Create a second Alias record pointing to the standby environment for failover.
Replication Slots: What Could Go Wrong
When a DMS task starts, Postgres creates replication slots that hold WAL logs. These slots keep WAL files on disk until DMS reads them.
If you stop the DMS task without deleting the replication slot, the slot keeps growing and can fill up your disk.
When you stop a DMS task, delete the replication slot on the primary database first. Otherwise, you risk running out of space.
Useful Queries
Check Replication Slot Status
SELECT slot_name, pg_size_pretty(pg_wal_lsn_diff(pg_current_wal_lsn(), restart_lsn)) AS replication_lag, active FROM pg_replication_slots;
This shows:
slot_name- the slot’s namereplication_lag- how far behind the replica isactive- whether the slot is currently being used
A high replication lag means the replica is falling behind. The active column shows ‘t’ for active slots and ‘f’ for idle ones.
Delete a Replication Slot
SELECT pg_drop_replication_slot('your_slot_name');
Only do this when replication is stopped. Dropping an active slot can break replication and lose data.
Important Notes
- Replication slots hold WAL files until DMS reads them. If DMS stops, the slots grow.
- Always have a backup before making changes to your database.
- Check the official PostgreSQL and AWS documentation for the latest best practices.
FAQ
Q: What is a replication slot?
A: A replication slot is a Postgres feature that tracks which WAL records have been sent to and applied by replicas. It prevents WAL from being recycled before replicas receive them.
Q: What happens if my replication slot fills up disk space?
A: If the slot isn’t being consumed (DMS stops reading), WAL files accumulate. You must either resume consumption or drop the slot to free space.
Q: Do I need to restart RDS after enabling logical replication?
A: Yes. Setting rds.logical_replication to 1 requires a restart because it’s a static parameter.
Q: Can I use RDS Blue/Green Deployments instead of DMS?
A: Yes. AWS now supports blue/green deployments natively for RDS. This is simpler than setting up DMS manually and handles the switchover for you. Check the AWS documentation for details.
Q: What about PostgreSQL version upgrades with blue/green?
A: You can upgrade the major or minor engine version in the green environment, test it, then switch over. The switchover typically takes under a minute.
Explore more like this

Aurora Serverless v2 + Bedrock: AI Database Queries in 2026
I connected Bedrock to our Aurora cluster last month. The first thing I asked it was “show me all customers who churned in Q1 but came back in Q2” —...

AWS WAF Rules Deep Dive: Rate-Based, Geo, and Custom Rules
WAF is one of those services where the default managed rules get you 80% of the way there. The last 20% is where it gets interesting.


Comments