AWS S3 Batch Operations: A Comprehensive Guide

AWS S3 Batch Operations
S3 Batch Operations lets you run large-scale jobs against objects in S3. You provide a manifest (a list of objects), pick an operation, and AWS handles the execution and scaling. Instead of looping through objects one by one with Lambda, you can process millions or billions of objects in a single batch job.
What is S3 Batch Operations, and when would you use it?
S3 Batch Operations is useful when you need to perform the same action across many S3 objects. Here are typical operations:
- Copy objects between buckets
- Set or change object storage classes
- Trigger an Amazon S3 event
- Run AWS Lambda functions
- Encrypt or decrypt objects using server-side encryption
- Set or update object tags and metadata
- Set or update access control lists (ACLs)
- Initiate Glacier restores
- Apply object retention policies
- Generate inventory reports
One thing to note: you can run only one operation per batch job, but that job can act on billions of objects.
Integrated Services
S3 Batch Operations works with several other AWS services:
- Amazon Glacier: Archive data to Glacier for cheaper storage
- AWS Lambda: Invoke Lambda functions as part of batch processing
- Amazon CloudWatch Events: Schedule or trigger batch jobs based on events
- Amazon SNS: Get notifications when jobs complete or fail
- Amazon SES: Send email notifications on job completion or errors
- Amazon DynamoDB: Use DynamoDB as a source or destination for processed data
Key Features
- Job Cloning: Duplicate an existing job, modify its parameters, and resubmit it. This is handy when a job fails partway through and you want to restart from where it left off.
- Programmatic Job Creation: You can automatically create and launch batch jobs by having a Lambda function trigger when an inventory report arrives.
- Job Priorities: Multiple jobs can run in the same region. Higher priority jobs go first. You can adjust priority on running jobs.
- CSV Object Lists: If your objects don’t share a common prefix, you can build a CSV manifest manually. Generate an inventory report first, filter to the objects you need, and use that CSV as your manifest.
Manifest and ETag
The manifest tells S3 Batch Operations which objects to process. You can generate one from an S3 Inventory report or create a CSV manually with bucket name, object key, and optionally the version ID.
Each object in the manifest has an ETag that S3 uses to track it. If an object changes during job execution, the ETag won’t match and the job will fail for that object. This prevents you from processing stale data.
Why use S3 Batch Operations instead of Lambda alone?
Lambda is great for event-driven processing, but it has limits. If you have millions of objects and you need to process all of them, triggering Lambda for each one individually gets expensive and slow. S3 Batch Operations handles the orchestration for you and can process objects in parallel across many workers.
Also, Lambda has runtime limits (15 minutes max). S3 Batch Operations doesn’t have this constraint, so it’s better for long-running operations.
How to set up an S3 Batch Operation
- Create an IAM role with permissions to read your manifest, perform your chosen operation, and write any output (like completion reports).
- Grant S3 Batch Operations permissions: You’ll need
s3:CreateJobandiam:PassRolepermissions. If your objects are encrypted with KMS, you’ll need to allow the role to use your KMS keys. - Create your manifest: Either use an S3 Inventory report or create a CSV file with the objects you want to process.
- Create the batch job: Specify the manifest location, the operation to perform, the IAM role, and optional settings like priority or SNS notifications.
- Run and monitor: Start the job and track progress in the S3 console or via CloudWatch metrics.
S3 Inventory and Batch Operations
S3 Inventory generates reports that list all objects in a bucket along with their metadata. You can use these reports as manifests for Batch Operations. This workflow is common for operations like copying all objects from one bucket to another, or applying new tags to everything.
Permissions recap
Make sure your batch job role has:
s3:GetObjectands3:GetObjectVersionto read the manifest and source objects- The specific permission for the operation you’re performing (e.g.,
s3:PutObjectTagging) s3:GetBucketLocationfor buckets in different regionskms:Decryptandkms:Encryptif you’re working with KMS-encrypted objects
Common Use Cases
S3 Batch Operations shows up in a lot of everyday AWS work:
- Cross-region replication: Copy objects from a bucket in one region to another
- Encryption migrations: Re-encrypt objects with a new KMS key
- Tag management: Add or update tags across millions of objects for cost tracking or lifecycle policies
- Glacier restores: Initiate restores for objects you want to move back to S3
- Format conversions: Use Lambda in a batch job to transform data (for example, transcoding videos)
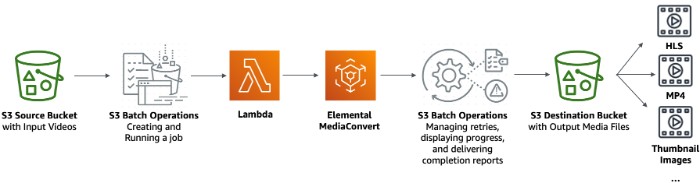
Real example: Video transcoding
Suppose you have a library of videos in S3 and you want to transcode them into different formats for different devices. Here’s how you might set this up:
- Store your source videos in one S3 bucket
- Create a Lambda function that uses AWS Elemental MediaConvert to transcode videos
- Generate an inventory report or CSV manifest of your source videos
- Create an S3 Batch Operations job that invokes your Lambda for each video
- Store the transcoded videos in a destination bucket
More examples
- Automated archival: As objects age, use S3 Batch Operations to move them to cheaper storage classes or Glacier.
- Image resizing: Process uploaded images through Lambda to create thumbnails at different sizes.
- Data transformation: Pull data from various sources into S3, transform it with Glue or Lambda, and load it into Redshift or Athena for analysis.
Getting started
To try S3 Batch Operations yourself:
- Pick a bucket and decide what operation you want to run
- Create a manifest of the objects you want to process
- Set up an IAM role with the right permissions
- Create your first batch job in the S3 console
Start small with a handful of objects to get familiar with the workflow before running jobs that affect millions of items.
Wrapping up
S3 Batch Operations is one of those AWS tools that can save you a lot of time once you understand it. Instead of building custom loops in Lambda or writing scripts that run for hours, you can offload the orchestration to AWS. It’s especially valuable for one-time migrations, large-scale updates, or recurring batch work that doesn’t need real-time processing.
Explore more like this

Golden AMI Pipelines with EC2 Image Builder and AWS CDK L2 Constructs
An EC2 Image Builder component is immutable. Change one line and you need a new version. The recipe referencing that component is immutable too, and the pipeline references the recipe....

CloudFormation Pre-Deployment Validation: Safer CDK and Stack Operations
CloudFormation now runs pre-deployment validation automatically on every CreateStack and UpdateStack operation, not only while creating change sets. A malformed property or resource-name collision can fail before AWS provisions or...


Comments